Put simply, usability evaluation assesses the extent to which an interactive system is easy and pleasant to use. Things aren’t this simple at all though, but let’s start by considering the following propositions about usability evaluation:
Usability is an inherent measurable property of all interactive digital technologies
Human-Computer Interaction researchers and Interaction Design professionals have developed evaluation methods that determine whether or not an interactive system or device is usable.
Where a system or device is usable, usability evaluation methods also determine the extent of its usability, through the use of robust, objective and reliable metrics
Evaluation methods and metrics are thoroughly documented in the Human-Computer Interaction research and practitioner literature. People wishing to develop expertise in usability measurement and evaluation can read about these methods, learn how to apply them, and become proficient in determining whether or not an interactive system or device is usable, and if so, to what extent.
The above propositions represent an ideal. We need to understand where current research and practice fall short of this ideal, and to what extent. Where there are still gaps between ideals and realities, we need to understand how methods and metrics can be improved to close this gap. As with any intellectual endeavour, we should proceed with an open mind, and acknowledge that not only are some or all of the above propositions not true, but that they can never be so. We may have to close some doors here, but in doing so, we will be better equipped to open new ones, and even go through them.
15.1 From First World Oppression to Third World Empowerment
Usability has been a fundamental concept for Interaction Design research and practice, since the dawn of Human-Computer Interaction (HCI) as an inter-disciplinary endeavour. For some, it was and remains HCI’s core concept. For others, it remains important, but only as one of several key concerns for interaction design.
It would be good to start with a definition of usability, but we are in contended territory here. Definitions will be presented in relation to specific positions on usability. You must choose one that fits your design philosophy. Three alternative definitions are offered below.
It would also be good to describe how usability is evaluated, but alternative understandings of usability result in different practices. Professional practice is very varied, and much does not generalise from one project to the next. Evaluators must choose how to evaluate. Evaluations have to be designed, and designing requires making choices.
15.1.1 The Origins of HCI and Usability
HCI and usability have their origins in the falling prices of computers in the 1980s, when for the first time, it was feasible for many employees to have their own personal computer (a.k.a PC). For their first three decades of computing, almost all users were highly trained specialists of expensive centralised equipment. A trend towards less well trained users began in the 1960s with the introduction of timesharing and minicomputers. With the use of PCs in the 1980s, computer users increasingly had no, or only basic, training on operating systems and applications software. However, software design practices continued to implicitly assume knowledgeable and competent users, who would be familiar with technical vocabularies and systems architectures, and also possess an aptitude for solving problems arising from computer usage. Such implicit assumptions rapidly became unacceptable. For the typical user, interactive computing became associated with constant frustrations and consequent anxieties. Computers were obviously too hard to use for most users, and often absolutely unusable. Usability thus became a key goal for the design of any interactive software that would not be used by trained technical computer specialists. Popular terms such as “user-friendly” entered everyday use. Both usability and user-friendliness were initially understood to be a property of interactive software. Software either was usable or not. Unusable software could be made usable through re-design.

Author/Copyright holder: Courtesy of Boffy b Copyright terms and licence: CC-Att-SA-3 (Creative Commons Attribution-ShareAlike 3.0).

Author/Copyright holder: Courtesy of Jeremy Banks. Copyright terms and licence: CC-Att-2 (Creative Commons Attribution 2.0 Unported).
Author/Copyright holder: Courtesy of Berkeley Lab. Copyright terms and licence: pd (Public Domain (information that is common property and contains no original authorship)).
Figure 15.1 A-B-C: The Home Personal Computer (PC) and Associated Peripherals is Now an Everyday Sight in Homes Worldwide. Usability became a critical issue with PC’s introduction.
15.1.2 From Usability to User Experience via Quality in Use
During the 1990s, more sophisticated understandings of usability shifted from an all-or-nothing binary property to a continuum spanning different extents of usability. At the same time, the focus of HCI shifted to contexts of use (Cockton 2004). Usability ceased to be HCI’s dominant concept, with research increasingly focused on the fit between interactive software and its surrounding usage contexts. Quality in use no longer appeared to be a simple issue of how inherently usable an interactive system was, but how well it fitted its context of use. Quality in use became a preferred alternative term to usability in international standards work, since it avoided implications of usability being an absolute context-free invariant property of an interactive system. Around the turn of the century, the rise of networked digital media (e.g., web, mobile, interactive TV, public installations) added novel emotional concerns for HCI, giving rise to yet another more attractive term than usability: user experience.
Current understandings of usability are thus different from those from the early days of HCI in the 1980s. Since then, ease of use has improved though both attention to interaction design and improved levels of IT literacy across much of the population in advanced economies. Familiarity with basic computer operations is now widespread, as evidenced by terms such as “digital natives” and “digital exclusion”, which would have had little traction in the 1980s. Usability is no longer automatically the dominant concern in interaction design. It remains important, with frustrating experiences of difficult to use digital technologies still commonplace. Poor usability is still with us, but we have moved on from Thomas Landauer’s 1996 Trouble with Computers (Landauer 1996). When PCs, mobile phones and the internet are instrumental in major international upheavals such as the Arab Spring of 2011, the value of digital technologies can massively eclipse their shortcomings.
15.1.3 From Trouble with Computers to Trouble from Digital Technologies
Readers from developing countries can today experience Landauer’s Trouble with Computers as the moans of oversensitive poorly motivated western users. On 26th January 1999, a "hole in the wall" was carved at the NIIT premises in New Delhi. Through this hole, a freely accessible computer was made available for people in the adjoining slum of Kalkaji. It became an instant hit, especially with children who, with no prior experience, learnt to use the computer on their own. This prompted NIIT’s Dr. Mitra to propose the following hypothesis:
The acquisition of basic computing skills by any set of children can be achieved through incidental learning provided the learners are given access to a suitable computing facility, with entertaining and motivating content and some minimal (human) guidance
-- http: //www.hole-in-the-wall.com/Beginnings.html
There is a strong contrast here with the usability crisis of the 1980s. Computers in 1999 were easier to use than those from the 1980s, but they still presented usage challenges. Nevertheless, residual usability irritations have limited relevance for this century’s slum children in Kalkaji.
The world is complex, what matters to people is complex, digital technologies are diverse. In the midst of this diverse complexity, there can't be a simple day of judgement when digital technologies are sent to usability heaven or unusable hell.
The story of usability is a perverse journey from simplicity to complexity. Digital technologies have evolved so rapidly that intellectual understandings of usability have never kept pace with the realities of computer usage. The pain of old and new world corporations struggling to secure returns on investment in IT in the 1980s has no rendezvous with the use of social media in the struggles for democracy in third world dictatorships. Yet we cannot simply discard the concept of usability and move on. Usage can still be frustrating, annoying, unnecessarily difficult and even impossible, even for the most skilled and experienced of users.

Copyright terms and licence: All Rights Reserved. Used without permission under the Fair Use Doctrine (as permission could not be obtained). See the "Exceptions" section (and subsection "allRightsReserved-UsedWithoutPermission") on the page copyright notice.
Figure 15.2: NIIT’s "hole in the wall” Computer in New Delhi

Copyright terms and licence: All Rights Reserved. Used without permission under the Fair Use Doctrine (as permission could not be obtained). See the "Exceptions" section (and subsection "allRightsReserved-UsedWithoutPermission") on the page copyright notice.
Figure 15.3: NIIT’s "hole in the wall” Computer in New Delhi
15.1.4 From HCI's sole concern to an enduring important factor in user experience
This encyclopaedia entry is not a requiem for usability. Although now buried under broader layers of quality in use and user experience, usability is not dead. For example, I provide some occasional IT support to my daughter via SMS. Once, I had to explain how to force the restart of a recalcitrant stalled laptop. Her last message to me on her problem was:
It's fixed now! I didn't know holding down the power button did something different to just pressing it.
Given the hidden nature of this functionality (a short press hibernates many laptops), it is no wonder that my daughter was unaware of the existence of a longer ‘holding down’ action. Also, given the rare occurrences of a frozen laptop, my daughter would have had few chances to learn. She had to rely on my knowledge here. There is little she could have known herself without prior experience (e.g., of iPhone power down).

Author/Copyright holder: Courtesy of Rico Shen. Copyright terms and licence: CC-Att-SA-3 (Creative Commons Attribution-ShareAlike 3.0).
Figure 15.4: Holding or Pressing? Who’s to Know?
The enduring realities of computer use that usability seeks to encompass remain real and no less potentially damaging to the success of designs today than over thirty years ago. As with all disciplinary histories, the new has not erased the old, but instead, like geological strata, the new overlies the old, with outcrops of usability still exposed within the wider evolving landscape of user experience. As in geology, we need to understand the present intellectual landscape in terms of its underlying historical processes and upheavals.
What follows is thus not a journey through a landscape, but a series of excavations that reveal what usability has been at different points in different places over the last three decades. With this in place, attention is refocused on current changes in the interaction design landscape that should give usability a stable place within a broader understanding of designing for human values (Harper et al. 2008). But for now, let us begin at the beginning, and from there take a whistle stop tour of HCI history to reveal unresolved tensions over the nature of usability and its relation to interaction design.
15.2 From Usability to User Experience - Tensions and Methods
The need to design interactive software that could be used with a basic understanding of computer hardware and operating systems was first recognised in the 1970s, with pioneering work within software design by Fred Hansen from Carnegie Mellon University (CMU), Tony Wasserman from University of California, San Francisco (UCSF), Alan Kay from Xerox Palo Alto Research Center (PARC), Engel and Granda from IBM, and Pew and Rollins from BBN Technologies (for a review of early HCI work, see Pew 2002). This work took several approaches, from detailed design guidelines to high level principles for both software designs and their development processes. It brought together knowledge and capabilities from psychology and computer science. The pioneering group of individuals here was known as the Software Psychology Society, beginning in 1976 and based in the Washington DC area (Shneiderman 1986). This collaboration between academics and practitioners from cognitive psychology and computer science forged approaches to research and practice that remained the dominant paradigm in Interaction Design research for almost 20 years, and retained a strong hold for a further decade. However, this collaboration contained a tension on the nature of usability.
The initial focus was largely cognitive, focusing on causal relationships between user interface features and human performance, but with different views on how user interface features and human attributes would interact. If human cognitive attributes are fixed and universal, then user interface features can be inherently usable or unusable, making usability an inherent binary property of interactive software, i.e., an interactive system simply is or is not usable. Software could be inherently usable by conformance to guidelines and principles that could be discovered, formulated and validated by psychological experiments. However, if human cognitive attributes vary not only between individuals, but across different settings, then usability becomes an emergent property that depends, not only on features and qualities of an interactive system, but also on who was using it, and on what they were trying to do with it. The latter position was greatly strengthened in the 1990s by the “turn to the social” (Rogers et al. 1994). However, much of the intellectual tension here was defused as HCI research spread out across a range of specialist communities focused on the Association for Computing Machinery’s conferences such as the ACM Conference on Computer Supported Cooperative Work (CSCW) from 1986 or the ACM Symposium on User Interface Software and Technology (UIST) from 1988. Social understandings of usability became associated with CSCW, and technological ones with UIST.
Psychologically-based research on usability methods in major conferences remained strong into the early 1990s. However, usability practitioners became dissatisfied with academic research venues, and the first UPA (Usability Professionals Association) conference was organised in 1992. This practitioner schism happened only 10 years after the Software Psychology Society had co-ordinated a conference in Gaithersburg, from which the ACM CHI conference series emerged. This steadily removed much applied usability research from the view of mainstream HCI researchers. This separation has been overcome to some extent by the UPA’s open access Journal of Usability Studies, which was inaugurated in 2005.

Author/Copyright holder: Ben Shneiderman and Addison-Wesley. Copyright terms and licence: All Rights Reserved. Reproduced with permission. See section "Exceptions" in the copyright terms below.
Figure 15.5: Ben Shneiderman, Software Psychology Pioneer, Authored the First HCI Textbook
15.2.1 New Methods, Damaged Merchandise and a Chilling Fact
There is thus a dilemma at the heart of the concept of usability: is it a property of systems or a property of usage? A consequence of 1990s fragmentation within HCI research was such important conceptual issues were brushed aside in favour of pragmatism amongst those researchers and practitioners who retained a specialist interest in usability. By the early 1990s, a range of methods had been developed for evaluating usability. User Testing (Dumas and Redish 1993) was well established by the late 1980s, as essentially a variant of psychology experiments with only dependent variables (the interactive system being tested became the independent constant). Discount methods included rapid low cost user testing, as well as inspection methods such as Heuristic Evaluation (Nielsen 1994). Research on model-based methods such as the GOMS model (Goals, Operators, Methods, and Selection rules - John and Kieras 1996) continued, but with mainstream publications becoming rarer by 2000.
With a choice of inspection, model-based and empirical (e.g., user testing) evaluation methods, questions arose as to which evaluation method was best and when and why. Experimental studies attempted to answer these questions by treating evaluation methods as independent variables in comparison studies that typically used problem counts and/or problem classifications as dependent variables. However, usability methods are too incompletely specified to be consistently applied, letting Wayne Gray and Marilyn Salzman invalidate several key studies in their Damaged Merchandise paper of 1998. Commentaries on their paper failed to undo the damage of the Damaged Merchandise charge, with further papers in the first decade of this century adding more concerns over not only method comparison, but the validity of usability methods themselves. Thus in 2001, Morten Hertzum and Niels Jacobsen published their “chilling fact” about use of usability methods: there are substantial evaluator effects. This should not have surprised anyone with a strong grasp of Gray and Salzman’s critique, since inconsistencies in usability method use make valid comparisons close to impossible in formal studies, and they are even more extensive in studies that attempt no control.
Critical analyses by Gray and Salzman, and by Hertzum and Jacobsen, made pragmatic research on usability even less attractive for leading HCI journals and conferences. The method focus of usability research shrunk, with critiques exposing not only the consequences of ambivalence over the causes of poor usability (system, user or both?), but also the lack of agreement over what was covered by the term usability.

Author/Copyright holder: Courtesy of kinnigurl. Copyright terms and licence: CC-Att-SA-2 (Creative Commons Attribution-ShareAlike 2.0 Unported).
Figure 15.6: 2020 Usability Evaluation Method Medal Winners
15.2.2 We Can Work it Out: Putting Evaluation Methods in their (Work) Place
Research on usability and methods has since the late 00s been superseded by research on user experience and usability work. User experience is a broader concept than usability, and moves beyond efficiency, task quality and vague user satisfaction to a wide consideration of cognitive, affective, social and physical aspects of interaction.
Usability work is the work carried out by usability specialists. Methods contribute to this work. Methods are not used in isolation, and should not be assessed in isolation. Assessing methods in isolation ignores the fact that usability work combines, configures and adapts multiple methods in specific project or organisational contexts. Recognition of this fact is reflected in an expansion of research focus from usability methods to usability work, e.g., is in PhDs (Dominic Furniss, Tobias Uldall-Espersen, Mie Nørgaard) associated with the European MAUSE project (COST Action 294, 2004-2009). It is also demonstrated in the collaborative research of MAUSE Working Group 2 (Cockton and Woolrych 2009).
A focus on actual work allows realism about design and evaluation methods. Methods are only one aspect of usability work. They are not a separate component of usability work that has deterministic effects, i.e., effects that are guaranteed to occur and be identical across all project and organisational contexts. Instead, broad evaluator effects are to be expected, due to the varying extent and quality of design and evaluation resources in different development settings. This means that we cannot and should not assess usability evaluation methods in artificial isolated research settings. Instead, research should start with the concrete realities of usability work, and within that, research should explore the true nature of evaluation methods and their impact.

Author/Copyright holder: Unknown (pending investigation). Copyright terms and licence: Unknown (pending investigation). See section "Exceptions" in the copyright terms below.
Figure 15.7: Usability Expert at Work: Alan Woolrych at the University of Sunderland using a minimal Mobile Usability Lab setup of webcam with audio recording plus recording of PC screen and sound, complemented by an eye tracker to his right
15.2.3 The Long and Winding Road: Usability's Journey from Then to Now
Usability is now one aspect of user experience, and usability methods are now one loosely pre-configured area of user experience work. Even so, usability remains important. The value of the recent widening focus to user experience is that it places usability work in context. Usability work is no longer expected to establish its value in isolation, but is instead one of several complementary contributors to design quality.
Usability as a core focus within HCI has thus passed through phases of psychological theory, methodological pragmatism and intellectual disillusionment. More recent foci on quality in use and user experience make it clear that Interaction Design cannot just focus on features and attributes of interactive software. Instead, we must focus on the interaction of users and software in specific settings. We cannot reason solely in terms of whether software is inherently usable or not, but instead have to consider what does or will happen when software is used, whether successfully, unsuccessfully, or some mix of both. Once we focus on interaction, a wider view is inevitable, favouring a broad range of concerns over a narrow focus on software and hardware features.

Author/Copyright holder: Unknown (pending investigation). Copyright terms and licence: Unknown (pending investigation). See section "Exceptions" in the copyright terms below.

Author/Copyright holder: Unknown (pending investigation). Copyright terms and licence: Unknown (pending investigation). See section "Exceptions" in the copyright terms below.
Figure 15.8 A-B: What’s Sailable: A Boat Alone or a Crewed Boat in Specific Sea Conditions? A Similar Question Arises for Usable Systems
Many of the original concerns of 1980s usability work are as valid today as they were 30 years ago. What has changed is that we no longer expect usability to be the only, or even the dominant, human factor in the success of interactive systems. What has not changed is the potential confusion over what usability is, which has existed from the first days of HCI, i.e., whether software or usage is usable. While this may feel like some irrelevant philosophical hair-splitting, it has major consequences for usability evaluation. If software can be inherently usable, then usability can be evaluated solely through direct inspection. If usability can only be established by considering usage, then indirect inspection methods (walkthroughs) or empirical user testing methods must be used to evaluate.
15.2.4 Usability Futures: From Understanding Tensions to Resolving Them
The form of the word ‘usability’ implies a property that requires an essentialist position, i.e., one that sees properties and attributes as been inherent in objects, both natural and artificial (in Philosophy, this is called an essentialist or substantivist ontology). A literal understanding of usability requires interactive software to be inherently usable or unusable. Although a more realistic understanding sees usability as a property of interactive use and not of software alone, it makes no sense to talk of use as being usable, just as it makes no sense to talk of eating being edible. This is why the term quality in use is preferred for some international standards, because this opens up a space of possible qualities of interactive performance, both in terms of what is experienced, and in terms of what is achieved, for example, an interaction can be ‘successful’, ‘worthwhile’, ‘frustrating’, ‘unpleasant’, ‘challenging’ or ‘ineffective’.
Much of the story of usability reflects a tension between the tight software view and the broader sociotechnical view of system boundaries. More abstractly, this is a tension between substance (essence) and relation, i.e., between inherent qualities of interactive software and emergent qualities of interaction. In philosophy, the position that relations are more fundamental than things in themselves characterises a relational ontology.
Ontologies are theories of being, existence and reality. They lead to very different understandings of the world. Technical specialists and many psychologists within HCI are drawn to essentialist ontologies, and seek to achieve usability predominantly through consideration of user interface features. Specialists with a broader human-focus are mostly drawn to relational ontologies, and seek to understand how contextual factors interact with user interface features to shape experience and performance. Each ontology occupies ground within the HCI landscape. Both are now reviewed in turn. Usability evaluation methods are then briefly reviewed. While tensions between these two positions have dominated the evolution of usability in principle and practice, we can escape the impasse. A strategy for escaping longstanding tensions within usability will be presented, and future directions for usability within user experience frameworks will be indicated in the closing section.
15.3 Locating Usability within Software: Guidelines, Heuristics, Patterns and ISO 9126
15.3.1 Guidelines for Usable User Interfaces
Much early guidance on usability came from computer scientists such as Fred Hansen from Carnegie Mellon University (CMU) and Tony Wasserman, then at University of California, San Francisco (UCSF). Computer science has been strongly influenced by mathematics, where entities such as similar or equilateral triangles have eternal absolute intrinsic properties. Computer scientists seek to establish similar inherent properties for computer programs, including ones that ensure usability for interactive software. Thus initial guidelines on user interface design incorporated a technocentric belief that usability could be ensured via software and hardware features alone. A user interface would be inherently usable if it conformed to guidelines on, for example, naming, ordering and grouping of menu options, prompting for input types, input formats and value ranges for data entry fields, error message structure, response time, and undoing capabilities. The following four example guidelines are taken from Smith and Mosier’s 1986 collection commissioned by the US Air Force (Smith and Mosier 1986):
1.0/4 + Fast Response
Ensure that the computer will acknowledge data entry actions rapidly, so that users are not slowed or paced by delays in computer response; for normal operation, delays in displayed feedback should not exceed 0.2 seconds.
1.0/15 Keeping Data Items Short
For coded data, numbers, etc., keep data entries short, so that the length of an individual item will not exceed 5-7 characters.
1.0/16 + Partitioning Long Data Items
When a long data item must be entered, it should be partitioned into shorter symbol groups for both entry and display.
Example
A 10-digit telephone number can be entered as three groups, NNN-NNN-NNNN.
1.4/12 + Marking Required and Optional Data Fields
In designing form displays, distinguish clearly and consistently between required and optional entry fields.
Figure 15.9: Four example guidelines taken from Smith and Mosier’s 1986 collection
25 years after the publication of the above guidance, there are still many contemporary web site data entry forms whose users would benefit from adherence to these guidelines. Even so, while following guidelines can greatly improve software usability, it cannot guarantee it.
Author/Copyright holder: Sidney L. Smith and Jane N. Mosier and The MITRE Corporation. Copyright terms and licence: All Rights Reserved. Reproduced with permission. See section "Exceptions" in the copyright terms below.
Figure 15.10: This Book Contains More Guidelines Than Anyone Could Imagine
15.3.2 Manageable Guidance: Design Heuristics for Usable User Interfaces
My original paper copy of Smith and Mosier’s guidelines occupies 10cm of valuable shelf space. It is over 25 years old and I have never read all of it. I most probably never will. There are simply too many guidelines there to make this worthwhile (in contrast, I have read complete style guides for Windows and Apple user interfaces in the past).
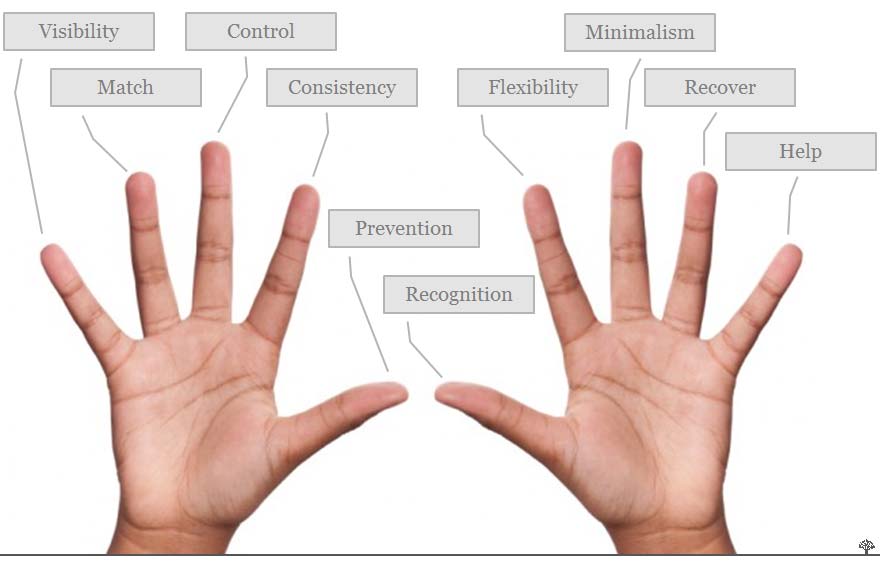
The bloat of guidelines collections did not remove the appeal of technocentric views of usability. Instead, hundreds of guidelines were distilled into ten heuristics by Rolf Molich and Jakob Nielsen. These were further assessed and refined into the final version of in Heuristic Evaluation (Nielsen 1994), an inspection method that examines software features for potential causes of poor usability. Heuristics generalise more detailed guidelines from collections such as Smith and Mosier. Many have a technocentric focus, e.g.:
Visibility of system status
The system should always keep users informed about what is going on, through appropriate feedback within reasonable time.
User control and freedom
Users often choose system functions by mistake and will need a clearly marked "emergency exit" to leave the unwanted state without having to go through an extended dialogue. Support undo and redo.
Error prevention
Even better than good error messages is a careful design which prevents a problem from occurring in the first place. Either eliminate error-prone conditions or check for them and present users with a confirmation option before they commit to the action.
Recognition rather than recall
Minimize the user's memory load by making objects, actions, and options visible. The user should not have to remember information from one part of the dialogue to another. Instructions for use of the system should be visible or easily retrievable whenever appropriate.
Flexibility and efficiency of use
Accelerators -- unseen by the novice user -- may often speed up the interaction for the expert user such that the system can cater to both inexperienced and experienced users. Allow users to tailor frequent actions.
Figure 15.11: Example heuristics orginally developed in Molich and Nielsen 1990 and Nielsen and Molich 1990
Heuristic Evaluation became the most popular user-centred design approach in the 1990s, but has become less prominent with the move away from desktop applications. Quick and dirty user testing soon overtook Heuristic Evaluation (compare the survey of Venturi et al. 2006 with Rosenbaum et al. 2000).
Author/Copyright holder: Unknown (pending investigation). Copyright terms and licence: Unknown (pending investigation). See section "Exceptions" in the copyright terms below.
Figure 15.12: One Heuristic for Each Digit from Nielsen
15.3.3 Invincible Intrinsics: Patterns and Standards Keep Usability Essential
Moves away from system-centric approaches within user-centred design have not signalled the end of usability methods that focus solely on software artefacts, with little or no attention to usage. This may be due to the separation of the usability communities (now user experience) from the software engineering profession. System-centredusability remains common in user interface pattern languages. For example, a pattern from Jenifer Tidwell updates Smith and Mosier style guidance for contemporary web designers (designinginterfaces.com/Input_Prompt).
Pattern: Input Prompt 
Prefill a text field or dropdown with a prompt that tells the user what to do or type.
Figure 15.13: An example pattern from Jenifer Tidwell's Designing Interfaces
The 1991 ISO 9126 standard on Software Engineering - Product Quality was strongly influenced by the essentialist preferences of computer science, with usability defined as:
a set of [product] attributes that bear on the effort needed for use, and on the individual assessment of such use, by a stated or implied set of users.
This is the first of three definitions presented in this encyclopaedia entry. The attributes here are assumed to be software product attributes, rather than user interaction ones. However, the relational (contextual) view of usage favoured in HCI has gradually come to prevail. By 2001, ISO 9126 had been revised to define usability as:
(1’) the capability of the software product to be understood, learned, used and attractive to the user, when used under specified conditions
This revision remains product focused (essentialist), but the ‘when’ clause moved IS0 9126 away from a wholly essentialist position on usability by implicitly acknowledging the influence of a context of use (“specified conditions”) that extends beyond “a stated or implied set of users”.
In an attempt to align the technical standard ISO 9126 with the human factors standard ISO 9241 (see below), ISO 9126 was extended in 2004 by a fourth section on quality in use, resulting in an uneasy compromise between software engineers and human factors experts. This uneasy compromise persists, with the 2011 replacement standard for ISO 9126, ISO 25010 maintaining an essentialist view of usability. In ISO 25010, usability is both an intrinsic product quality characteristic and a subset of quality in use (comprising effectiveness, efficiency and satisfaction). As a product characteristic in ISO 25010, usability has the intrinsic subcharacteristics of:
Appropriateness
Recognisability
Learnability
Operability (degree to which a product or system has attributes that make it easy to operate and control - emphasis added)
User error protection
User interface aesthetics
ISO 25010 thus had to include a note that exposed the internal conflict between software engineering and human factors world views:
Usability can either be specified or measured as a product quality characteristic in terms of its subcharacteristics, or specified or measured directly by measures that are a subset of quality in use.
A similar note appears for learnability and accessibility. Within the world of software engineering standards, a mathematical world view clings hard to an essentialist position on usability. In HCI, where context has reigned for decades, this could feel incredibly perverse. However, despite HCI’s multi-factorial understanding of usability, which follows automatically from a contextual position, HCI evangelists’ anger over poor usability always focuses on software products. Even though users, tasks and contexts are all known to influence usability, only hardware or software should be changed to improve usability, endorsing the software engineers’ position within ISO 25010 (attributes make software easy to operate and control). Although HCI’s world view typically rejects essentialist monocausal explanations of usability, when getting angry on the user’s behalf, the software always gets the blame.
It should be clear that issues here are easy to state but harder to unravel. The stalemate in ISO 25010 indicates a need within HCI to give more weight to the influence of software design on usability. If users, tasks and contexts must not be changed, then the only thing that we can change is hardware and/or software. Despite the psychological marginalisation of designers’ experience and expertise when expressed in guidelines, patterns and heuristics, these can be our most critical resource for achieving usability best practice. We should bear this in mind as we move to consider HCI’s dominant contextual position on usability.
15.4 Locating Usability within Interaction: Contexts of Use and ISO Standards
The tensions within international standards could be seen within Nielsen’s Heuristics, over a decade before the 2004 ISO 9126 compromise. While the five sample heuristics in the previous section focus on software attributes, one heuristic focuses on the relationship between a design and its context of use (Nielsen 1994):
Match between system and the real world
The system should speak the users' language, with words, phrases and concepts familiar to the user, rather than system-oriented terms. Follow real-world conventions, making information appear in a natural and logical order.
This relating of usability to the ‘real world’ was given more structure in the ISO 9241-11 Human Factors standard, which related usability to the usage context as the:
Extent to which a product can be used by specified users to achieve specified goals with effectiveness, efficiency and satisfaction in a specified context of use
This is the second of three definitions presented in this encyclopaedia entry. Unlike the initial and revised ISO 9126 definitions, it was not written by software engineers, but by human factors experts with backgrounds in ergonomics, psychology and similar.
ISO 9241-11 distinguishes three component factors of usability: effectiveness, efficiency, satisfaction. These result from multi-factorial interactions between users, goals, contexts and a software product. Usability is not a characteristic, property or quality, but an extent within a multi-dimensional space. This extent is evidenced by what people can actually achieve with a software product and the costs of these achievements. In practical terms, any judgement of usability is a holistic assessment that combines multi-faceted qualities into a single judgement.
Such single judgements have limited use. For practical purposes, it is more useful to focus on separate specific qualities of user experience, i.e., the extent to which thresholds are met for different qualities. For example, a software product may not be deemed usable if key tasks cannot be performed in normal operating contexts within an acceptable time. Here, the focus would be on efficiency criteria. There are many usage contexts where time is limited. The bases for time limits vary considerably, and include physics (ballistics in military combat), physiology (medical trauma), chemistry (process control) or social contracts (newsroom print/broadcast deadlines).
Effectiveness criteria add to the complexity of quality thresholds. A military system may be efficient, but it is not effective if its use results in what is euphemistically called ‘collateral damage’, including ‘friendly fire’ errors. We can imagine trauma resuscitation software that enables timely responses, but leads to avoidable ‘complications’ (another domain euphemism) after a patient has been stabilised. A process control system may support timely interventions, but may result in waste or environmental damage that limits the effectiveness of operators’ responses. Similarly, a newsroom system may support rapid preparation of content, but could obstruct the delivery of high quality copy.
For satisfaction, usage could be both objectively efficient and effective, but cause uncomfortable user experiences that give rise to high rates of staff turnover (as common in call centres). Similarly, employees may thoroughly enjoy a fancy multimedia fire safety training title, but it could be far less effective (and thus potentially deadly) compared to the effectiveness of a boring instructional text-with-pictures version.
ISO 9241-11’s three factors of usability have recently become five in by ISO 25010’s quality in use factors:
Effectiveness
Efficiency
Satisfaction
Freedom from risk
Context coverage
The two additional factors are interesting. Context coverage is a broader concept than the contextual fit of the match between system and Nielsen’s Match between System and Real World heuristic (Nielsen 1994). It extends specified users and specified goals to potentially any aspect of a context of use. This should include all factors relevant to freedom from risk, so it is interesting to see this given special attention, rather than trusting effectiveness and satisfaction to do the work here. However, such piecemeal extensions within ISO 25010 open up the question of comprehensiveness and emphasis. For example, why are factors such as ease of learning either overlooked or hidden inside efficiency or effectiveness?

Author/Copyright holder: ISO and Lionel Egger. Copyright terms and licence: All Rights Reserved. Reproduced with permission. See section "Exceptions" in the copyright terms below.
Figure 15.14: ISO Accessibility Standard Discussion
15.4.1 Contextual Coverage Brings Complex Design Agendas
Relational positions on usability are inherently more complex than essentialist ones. The latter let, interactive systems be inspected to assess their usability potential on the basis of their design features. Essentialist approaches remain attractive because evaluations can be fully resourced through guidelines, patterns and similar expressions of best practice for interaction design. Relational approaches require a more complex set of co-ordinated methods. As relational positions become more complex, as in the move from ISO 9241-11 to ISO 25010, a broader range of evaluation methods is required. Within the relational view, usability is the result of a set of complex interactions that manifests itself in a range of usage factors. It is very difficult to see how a single evaluation method could address all these factors. Whether or not this is possible, no such method currently exists.
Relational approaches to usability require a range of evaluation methods to establish its extent. Extent introduces further complexities, since all identified usability factors must be measured, then judgements must be made as to whether achieved extents are adequate. Here, usability evaluation is not a simple matter of inspection, but instead it becomes a complex logistical operation focused on implementing a design agenda.
An agenda is list of things to be done. A design agenda is therefore a list of design tasks, which need to be managed within an embracing development process. There is an implicit design agenda in ISO 9241-11, which requires interaction designers to identify target beneficiaries, usage goals, and levels of efficiency, effectiveness and satisfaction for a specific project. Only then is detailed robust usability evaluation possible. Note that this holds for ISO 9241-11 and similar evaluation philosophies. It does not hold for some other design philosophies (e.g., Sengers and Gaver 2006) that give rise to different design agendas.
A key task on the ISO 9241-11 evaluation agenda is thus measuring the extent of usability through a co-ordinated set of metrics, which will typically mix quantitative and qualitative measures, often with a strong bias towards one or the other. However, measures only enable evaluation. To evaluate, measures need to be accompanied by targets. Setting such targets is another key task from the ISO 9241-11 evaluation agenda. This is often achieved through the use of generic severity scales. To use such resources, evaluators need to interpret them in specific project contexts. This indicates that re-usable evaluation resources are not complete re-usable solutions. Work is required to turn these resources into actionable evaluation tasks.
For example, the two most serious levels of Chauncey Wilson’s problem severity scale (Wilson 1999) are:
Level 1 - Catastrophic error causing irrevocable loss of data or damage to the hardware or software. The problem could result in large-scale failures that prevent many people from doing their work. Performance is so bad that the system cannot accomplish business goals.
Level 2 - Severe problem causing possible loss of data. User has no workaround to the problem. Performance is so poor that ... universally regarded as 'pitiful'.
Each severity level requires answers to questions about specific measures and contextual information, i.e., how should the following be interpreted in a specific project context: ‘many prevented from doing work’; ‘cannot accomplish business goals’; ‘performance regarded as pitiful’. These top two levels also require information about the software product: ‘loss of data’; ‘damage to hardware of software’; ‘no workaround’.
Wilson’s three further lower level scales add considerations such as: ‘wasted time’, ‘increased error or learning rates’, and ‘important feature not working as expected’. These all set a design agenda of questions that must be answered. Thus to know that performance is regarded as pitiful, we would need to choose to measure relevant subjective judgments. Other criteria are more challenging, e.g., how would we know whether time is wasted, or whether business goals cannot be accomplished? The first depends on values. The idea of ‘wasting’ time (like money) is specific to some cultural contexts, and also depends on how long tasks are expected to take with a new system, and how much time can be spent on learning and exploring. As for business goals, a business may seek, for example, to be seen as socially and environmentally responsible, but may not expect every feature of every corporate system to support these goals.
Once thresholds for severity criteria have been specified, it is not clear how designers can or should trade off factors such as efficiency, effectiveness and satisfaction against each other. For example, users may not be satisfied even when they exceed target efficiency and effectiveness, or conversely they could be satisfied even when their performance should not warrant that relative to design targets. Target levels thus guide rather than dictate the interpretation of results and how to respond to them.
Method requirements thus differ significantly between essentialist and relational approaches to usability. For high quality evaluation based on any relational position, not just ISO 9241-11’s, evaluators must be able to modify and combine existing re-usable resources for specific project contexts. Ideally, the re-usable resources would do most of the work here, resulting in efficient, effective and satisfying usability evaluation. If this is not the case, then high quality usability evaluation will present complex logistical challenges that require extensive evaluator expertise and project specific resources.

Author/Copyright holder: Simon Christen - iseemooi. Copyright terms and licence: All Rights Reserved. Reproduced with permission. See section "Exceptions" in the copyright terms below.
Figure 15.15: Relational Approaches to Usability Require Multiple Measures
15.5 The Development of Usability Evaluation: Testing, Modelling and Inspection
Usability is a contested historical term that is difficult to replace. User experience specialists have to refer to usability, since it is a strongly established concept within the IT landscape. However, we need to exercise caution in our use of what is essentially a flawed concept. Software is not usable. Instead, software gets used, and the resulting user experiences are a composite of several qualities that are shaped by product attributes, user attributes and the wider context of use.
Now, squabbles over definitions will not necessarily impact practice in the ‘real world’. It is possible for common sense to prevail and find workarounds for what could well be semantic distractions with no practical import. However, when we examine usability evaluation methods, we do see that different conceptualisations of usability result in differences over the causes of good and poor usability.
Essentialist usability is, causally homogeneous. This means that all causes of user performance are of the same type, i.e., due to technology. System-centred inspection methods can identify such causes.
Contextual usability is causally heterogeneous. This means that causes of user performance are of different types, some due to technologies, others due to some aspect(s) of usage contexts, but most due to interactions between both. Several evaluation and other methods may be needed to identify and relate a nexus of causes.
Neither usability paradigm (i.e., essentialist or relational) has resolved the question of relevant effects, i.e., what counts as evidence of good or poor usability, and thus there are few adequate methods here. Essentialist usability can pay scant attention to effects (Lavery et al. 1997): who cares what poor design will do to users, it’s bad enough that it’s poor design! Contextual usability has more focus on effects, but there is limited consensus on the sort of effects that should count as evidence of poor usability. There are many examples of what could count as evidence, but what actually should is left to a design team’s judgement.
Some methods can predict effects. The GOMS model (Goals, Operators, Methods, and Selection rules) predicts effects on expert error free task completion time, which is useful in some project contexts (Card et al 1980, John and Kieras 1996). For example, external processes may require a task to be completed within a maximum time period. If predicted expert error free task completion time exceeds this, then it is highly probable that non-expert error prone task completion take even longer. Where interactive devices such as in-car systems distract attention from the main task (e.g., driving), then time predictions are vital. Recent developments such as CogTool (Bellamy et al. 2011) have given a new lease of life to practical model-based evaluation in HCI. More powerful models than GOMS are now being integrated into evaluation tools (e.g., Salvucci 2009).

Author/Copyright holder: Courtesy of Ed Brown. Copyright terms and licence: CC-Att-SA-2 (Creative Commons Attribution-ShareAlike 2.0 Unported).
Figure 15.16: Model-Based methods can predict how long drivers could be distracted, and much more.
Usability work can thus be expected to involve a mix of methods. The mix can be guided by high level distinctions between methods. Evaluation methods can be analytical (based on examination of an interactive system and/or potential interactions with it) or empirical (based on actual usage data). Some analytical methods require the construction of one or more models. For example, GOMS models the relationships between software and human performance. Software attributes in GOMS all relate to user input methods at increasing levels of abstraction from the keystroke level up to abstract command constructs. System and user actions are interleaved in task models to predict users’ methods (and execution times at a keystroke level of analysis).
15.5.1 Analytical and Empirical Evaluation Methods, and How to Mix Them
Analytical evaluation methods may be system-centred (e.g., Heuristic Evaluation) or interaction-centred (e.g., Cognitive Walkthrough). Design teams use the resources provided by a method (e.g., heuristics) to identify strong and weak elements of a design from a usability perspective. Inspection methods tend to focus on the causes of good or poor usability. System-centred inspection methods focus solely on software and hardware features for attributes that will promote or obstruct usability. Interaction-centred methods focus on two or more causal factors (i.e., software features, user characteristics, task demands, other contextual factors).
Empirical evaluation methods focus on evidence of good or poor usability, i.e., the positive or negative effects of attributes of software, hardware, user capabilities and usage environments. User testing is the main project-focused method. It uses project-specific resources such as test tasks, users, and also measuring instruments to expose usability problems that can arise in use. Also, essentialist usability can use empirical experiments to demonstrate superior usability arising from user interface components (e.g., text entry on mobile phones) or to optimise tuning parameters (e.g., timings of animations for windows opening and closing). Such experiments assume that the test tasks, test users and test contexts allow generalisation to other users, tasks and contexts. Such assumptions are readily broken, e.g., when users are very young or elderly, or have impaired movement or perception.
Analytical and empirical methods emerged in rapid succession, with empirical methods emerging first in the 1970s as simplified psychology experiments (for examples, see early volumes of International Journal of Man-Machine Studies 1969-79). Model-based approaches followed in the 1980s, but the most practical ones are all variants of the initial GOMS method (John and Kieras 1996). Model-free inspection methods appeared at the end of the 1980s, with rapid evolution in the early 1990s. Such methods sought to reduce the cost of usability evaluation by discounting across a range of resources, especially users (none required, unlike user testing), expertise (transferred by heuristics/models to novices) or extensive models (none required, unlike GOMS).

Author/Copyright holder: Old El Paso. Copyright terms and licence: All Rights Reserved. Used without permission under the Fair Use Doctrine (as permission could not be obtained). See the "Exceptions" section (and subsection "allRightsReserved-UsedWithoutPermission") on the page copyright notice.
Figure 15.17: Chicken Fajitas Kit: everything you need except chicken, onion, peppers, oil, knives, chopping board, frying pan, stove etc. Usability Evaluation Methods are very similar - everything is fine once you’ve worked to provide everything that’s missing
Achieving balance in a mix of evaluation methods is not straightforward, and requires more than simply combining analytical and empirical methods. This is because there is more to usability work than simply choosing and using methods. Evaluation methods are as complete as a Chicken Fajita Kit, which contains very little of what is actually needed to make Chicken Fajitas: no chicken, no onion, no peppers, no cooking oil, no knives for peeling/coring and slicing, no chopping board, no frying pan, no stoves etc. Similarly, user testing ‘methods’ as published miss out equally vital ingredients and project specific resources such as participant recruitment criteria, screening questionnaires, consent forms, test task selection criteria, test (de)briefing scripts, target thresholds, and even data collection instruments, evaluation measures, data collation formats, data analysis methods, or reporting formats. There is no complete published user testing method that novices can pick up and use ‘as is’. All user testing requires extensive project-specific planning and implementation. Instead, much usability work is about configuring and combining methods for project-specific use.
15.5.2 The Only Methods are the Ones that You Complete Yourselves
When planning usability work, it is important to recognise that so-called ‘methods’ are more strictly loose collections of resources better understood as ‘approaches’. There is much work in getting usability work to work, and as with all knowledge-based work, methods cannot copied from books and applied without a strong understanding of fundamental underlying concepts. One key consequence here is that only specific instances of methods can be compared in empirical studies, and thus credible research studies cannot be designed to collect evidence of systematic reliable differences between different usability evaluation methods. All methods have unique usage settings that require project-specific resources, e.g., for user testing, these include participant recruitment, test procedures and (de-)briefings. More generic resources such as problem extraction methods (Cockton and Lavery 1999) may also vary across user testing contexts. These inevitably obstruct reliable comparisons.

Author/Copyright holder: George Eastman House Collection. Copyright terms and licence: All Rights Reserved. Reproduced with permission. See section "Exceptions" in the copyright terms below.

Author/Copyright holder: George Eastman House Collection. Copyright terms and licence: All Rights Reserved. Reproduced with permission. See section "Exceptions" in the copyright terms below.
Figure 15.18 A-B: Dogs or Cats: which is the better pet? It all depends on what sorts of cats and dogs you compare, and how you compare them. The same is true of evaluation methods.
Consider a simple comparison of heuristic evaluation against user testing. Significant effort would be required to allow a fair comparison. For example, if the user testing asked test users to carry out fixed tasks, then heuristic evaluators would need to explore the same system using the same tasks. Any differences and similarities between evaluation results for the two methods would not generalise beyond these fixed tasks, and there are also likely to be extensive evaluation effects arising from individual differences in evaluator expertise and performance. If tasks are not specified for the evaluations, then it will not be clear whether differences and similarities between results are due to the approaches used or to the unrecorded tasks within for the evaluations. Given the range of resources that need to be configured for a specific user test, it is simply not possible to control all known potential confounds (still less all currently unknown ones). Without such controls, the main sources of differences between methods may be factors with no bearing on actual usability.
The tasks carried out by users (in user testing) or used by evaluators (in inspections or model specifications) are thus one possible confound when comparing evaluation approaches. So too are evaluation measures and target thresholds. Time on task is a convenient measure for usability, and for some usage contexts it is possible to specify worthwhile targets, e.g., for supermarket checkouts thetarget time to check out representative trolleys of purchases could be 30 minutes for 10 typical trolley loads of shopping). However, in many settings, there are no time thresholds for efficient use that can be used reliably (e.g., time to draft and print a one page business letter, as opposed to typing one in from a paper draft or a dictation).
Problems associated with setting thresholds are compounded by problems associated with choosing the measures for which thresholds are required. A wide range of potential measures can be chosen for user testing. For example, in 1988, usability specialists from Digital Equipment Corporation and IBM (Whiteside et al. 1988) published a long list of possible evaluation measures, including:
Measure without measure: there’s so much scope for scoring
Counts of:
commands used
repetitions of failed commands
runs of successes and of failures
good and bad features recalled by users
available commands not invoked/regressive behaviours
users preferring your system
Percentage of tasks completed in time period
Counts or percentages of:
errors
superior competitor products on a measure
Ratios of
successes to failures
favourable to unfavourable comments
Times
to complete a task
spent in errors
spent using help or documentation
Frequencies
of help and documentation use
of interfaces misleading users
users needing to work around a problem
users disrupted from a work task
users losing control of the system
users expressing frustration or satisfaction
No claims were made for the comprehensiveness of the full list of measures that were known to have been used up to the point of publication within Digital Equipment Corporation or IBM. What was clear was a position that project teams must choose their own metrics and thresholds. No methods yet exist to reliably support such choices.
There are no universal measures of usability that are relevant to every software development project. Interestingly, Whiteside et al. (1988) was the publication that first introduced contextual design to the HCI community. Its main message was that existing user testing practices were delivering far less value for design than contextual research. A hope was expressed that once contexts of use were better understood, and contextual insights could be shown to inform successful design across a diverse range of projects, then new contextual measures would be found for more appropriate evaluation of user experiences. Two decades elapsed before bases for realising this hope emerged within HCI research and professional practice. The final sections of this encyclopaedia entry explore possible ways forward.
15.5.3 Sorry to Disappoint You But ...
To sum up the position so far:
There are fundamental differences on the nature of usability, i.e., it is either an inherent property of interactive systems, or an emergent property of usage. There is no single definitive answer to what usability ‘is’. Usability is only an inherent measurable property of all interactive digital technologies for those who refuse to think of it in any other way.
There are no universal measures of usability, and no fixed thresholds above or below which all interactive systems are or are not usable. There are no universal, robust, objective and reliable metrics. There are no evaluation methods that unequivocally determine whether or not an interactive system or device is usable, or to what extent. All positions here involve hard won expertise, judgement calls, and project-specific resources beyond what all documented evaluation methods provide.
Usability work is too complex and project-specific to admit generalisable methods. What are called ‘methods’ are more realistically ‘approaches’ that provide loose sets of resources that need to be adapted and configured on a project by project basis. There are no reliable pre-formed methods for assessing usability. Each method in use is unique, and relies heavily on the skills and knowledge of evaluators, as well as on project-specific resources. There are no off-the-shelf evaluation methods. Evaluation methods and metrics are not completely documented in any literature. Developing expertise in usability measurement and evaluation requires far more than reading about methods, learning how to apply them, and through this alone, becoming proficient in determining whether or not an interactive system or device is usable, and if so, to what extent. Even system-centred essentialist methods leave gaps for evaluators to fill (Cockton et al. 2004, Cockton et al. 2012).
The above should be compared with the four opening propositions, which together constitute an attractive ideology that promises certainties regardless of evaluator experience and competence. Each proposition is not wholly true, and can be mostly false. Evaluation can never be an add-on to software development projects. Instead, the scope of usability work, and the methods used, need to be planned with other design and development activities. Usability evaluation requires supporting resources that are an integral part of every project, and must be developed there.
The tension between essentialist and relational conceptualisations of usability is only the tip of the iceberg of challenges for usability work. Not only is it not clear what usability is (although competing definitions are available), but it is also not clear specifically how usability should be assessed outside of the contexts of specific projects. What matters in one context may not matter in another. Project teams must decide what matters. The usability literature can indicate possible measure of usability, but none are universally applicable. The realities of usability work are that each project brings unique challenges that require experience and expertise to meet them. Novice evaluators cannot simply research, select and apply usability evaluation methods. Instead, actual methods in use are the critical achievement of all usability work.
Methods are made on the ground on a project by project basis. They are not archived ‘to go’ in the academic or professional literature. Instead there are two starting points. Firstly, there are literatures on a range of approaches that provide some re-usable resources for evaluators, but require additional information and judgement within project contexts before practical methods can be completed. Secondly, there are detailed case studies of usability work within specific projects. Here the challenge for evaluators is to identify resources and practices within the case study that would have a good fit with other project contexts, e.g., a participant recruitment procedure from a user testing case study may be re-usable in other projects, perhaps with some modifications.
Readers could reasonably draw the conclusion from the above that usability is an attractive idea in principle that has limited substance in reality. However, the reality is that we all continue to experience frustrations when using interactive digital technologies, and often we would say that we do find them difficult to use. Even so, frustrating user experiences may not be due to some single abstract construct called ‘usability’, but instead be the result of unique complex interactions between people, technology and usage contexts. Interacting factors here must be considered together. It is not possible to form judgements on the severity of isolated usage difficulties, user discomfort or dissatisfaction. Overall judgements on the quality of interactive software must balance what can be achieved through using it against the costs of this use. There are no successful digital technologies without what could be usability flaws to some HCI experts (I can always find some!). Some technologies appear to have severe flaws, and are yet highly successful for many users. Understanding why this is the case provides insights that move us away from a primary focus on usability in interaction design.
15.6 Worthwhile Usability: When and Why Usability Matters, and How Much
While writing the previous section, I sought advice via Facebook on transferring contacts from my vintage Nokia N96 mobile phone to my new iPhone. One piece of advice turned out to be specific to Apple computers, but was still half-correct for a wintel PC. Eventually, I identified a possible data path that required installing the Nokia PC suite on my current laptop, backing up contacts from my old phone to my laptop, downloading a freeware program that would convert contacts from Nokia’s proprietary backup format into a text format for spreadsheets/databases (comma separated values - .csv), failing to import it into a cloud service, importing it into the Windows Address Book on my laptop (after spreadsheet editing), and then finally synchronising the contacts instead via iTunes with my new iPhone.
15.6.1 A Very Low Frequency Multi-device Everyday Usability Story
From start to finish, my phone number transfer task took two and a half hours. Less than half of my contacts were successfully transferred, and due to problems in the spreadsheet editing, I had to transfer contacts in a form that required further editing on my iPhone or in the Windows contacts folder.
Focusing on the ISO 9241-11 definition of usability, what can we say here about the usability of a complex ad hoc overarching product-service system involving social networks, cloud computing resources, web searches, two component product-service systems (Nokia 96 + Nokia PC Suite, iPhone + iTunes) and Windows laptop utilities?
Author/Copyright holder: Unknown (pending investigation). Copyright terms and licence: Unknown (pending investigation). See section "Exceptions" in the copyright terms below.
Figure 15.19: A Tale of Two Mobiles and Several Software Utilities
Was it efficient taking 2.5 hours over this? Around 30 minutes each were spent on:
web searches, reading about possible solutions, and a freeware download
installing mobile phone software (new laptop since I bought the Nokia), attempts to connect Nokia to laptop, laptop restart, successful backup, extraction to .csv format with freeware
exploring a cloud email contacts service, failing to upload to it.
test upload to Windows address book, edits to improve imports, failed edits of phone numbers, successful import
Synchronisation of iPhone and iTunes
To reach a judgement on efficiency, we need to first bear in mind that during periods of waiting (uploads, downloads, synchronisations, installations), I proof read my current draft of this entry and corrected it. This would have taken 30 minutes anyway. Secondly, I found useful information from the web searches that lead me to the final solution. Thirdly, I had to learn how to use the iTunes synchronisation capabilities for iPhones, which took around 10 minutes and was an essential investment for the future. However, I wasted at least 30 minutes on a cloud computing option suggested on Facebook (I had to add email to the cloud service before failing to upload from the .csv file). There were clear usability issues here, as the email service gave no feedback as to why it was failing to upload the contacts. There is no excuse for such poor interaction design in 2011, which forced me to try a few times before I realised that it would not work, at least with the data that I had. Also, the extracted phone numbers had text prefixes, but global search and replace in the spreadsheet resulted in data format problems that I could not overcome. I regard both of these as usability problems, one due to the format of the telephone numbers as extracted, and one due to the bizarre behaviour of a well known spreadsheet programme.
I have still not answered the question of whether this was efficient in ISO 9241-11 terms. I have to conclude that it was not, but this was partly due to my lack of knowledge on co-ordinating a complex combination of devices and software utilities. However, back when contacts were only held on mobile phone SIMs, the transfer would have taken a few minutes in a phone store. So, current usability problems here are due to the move to storing contacts in more comprehensive formats separately from a mobile phone’s SIM. However, while there used to be a more efficient option, most of us now make use of more comprehensive phone memory contacts, and thus the previous fast option was at the cost of the most primitive contact format imaginable. So while the activity was relatively inefficient, there are potentially compensating reasons for this.
The only genuine usability problems relate to the lack of feedback in the cloud-based email facility, the extracted phone number formats, and bizarre spreadsheet behaviour. However, I only explored the cloud email option following advice via Facebook. My experience of problems here was highly contextual. For the other two problems, if the second problem had not existed, then I would never have experienced the third.
There are clear issues of efficiency. At best this took twice as long as it should have once interleaved work and much valuable re-usable learning are discounted. However, the causes of this inefficiency are hard to pin-point within the complex socially shaped context within which I was working.
Effectiveness is easy to evaluate. I only transferred just under 50% of the contacts. Note how straightforward the analysis is here when compared to efficiency in relation to a complex product-service system.
On balance, you may be surprised to read that I was fairly satisfied. Almost 50% is better than nothing. I learned how to synchronise my iPhone via iTunes for the first time. I made good use of the waits in editing this encyclopaedia entry. I was not in any way happy though, and I remain dissatisfied over the phone number formats, inscrutable spreadsheet behaviour and mute import facility on a top three free email facility.
15.6.2 And the Moral of My Story Is: It was Worth It, on Balance
What overall judgement can we come to here? On a binary basis, the final data path that I chose was usable. An abandoned path was not, so I did encounter one unusable component during my attempt to transfer phone numbers. As regards a more realistic extent of usability (as opposed to binary usable vs. unusable), we must trade off factors such as efficiency, effectiveness and satisfaction against each other. I could rate the final data path as 60% usable, with effective valuable learning counteracting the ineffective loss of over half of my contacts, which I had to subsequently enter manually. I could raise substantially this to 150% by adding the value of the resulting example for this encyclopaedia entry! It reveals the complexity of evaluating usability of interactions involving multiple devices and utilities. Describing usage is straightforward: judging its quality is not.
So, poor usability is still with us, but it tends to arise most often when we attempt to co-ordinate multiple digital devices across a composite ad-hoc product-service system. Forlizzi (2008) and others refer to these now typical usage contexts as product ecologies, although some (e.g., Harper et al. 2008) prefer the term product ecosystems, or product-service ecosystems (ecology is the discipline of ecosystems, not the systems themselves).
Components that are usable enough in isolation are less usable in combination. Essentialist positions on usability become totally untenable here, as the phone formats can blame the bizarre spreadsheet and vice-versa. The effects of poor usability are clear, but the causes are not. Ultimately, the extent of usability, and its causes in such settings, is a matter of interpretation based on judgements of the value achieved and the costs incurred.
Far from being an impasse, regarding usability as a matter of interpretation actually opens up a way forward for evaluating user experiences. It is possible to have robust interpretations of efficiency, effectiveness and satisfaction, and robust bases for overall assessments of how these trade-off against each other. To many, these bases will appear to be subjective, but this is not a problem, or at least it is far less of a problem than acting erroneously as if we have generic universal objective criteria for the existence or extent of usability in any interactive system. To continue any quest for such criteria is most definitely inefficient and ineffective, even if the associated loyalties to seventeenth century scientific values bring some measure of personal (subjective) satisfaction.
It is poor usability that focused HCI attention in the 1980s. There was no positive conception of good usability. Poor usability could degrade or even destroy the intended value of an interactive system. However, good usability can not donate value beyond that intended by a design team. Usability evaluation methods are focused on finding problems, not on finding successes (with the exception of Cognitive Walkthrough). Still, experienced usability practitioners know that an evaluation report should begin by commending the strong points of a design, but these are not what usability methods are optimised to detect.
Realistic relevant evaluations must assess incurred costs relative to achieved benefits. When transferring my contacts between phones, I experienced the following problems and associated costs:
Could not upload contacts into cloud email system, despite several attempts (cost: wasted 30 minutes)
Could not understand why I could not upload contacts into cloud email system (costs: prolonged frustration, annoyance, mild anger, abusing colleagues’ company #1)
Could not initiate data transfer from Nokia phone first time, requiring experiments and laptop restart as advised by Nokia diagnostics (cost: wasted 15 minutes)
Over half of my contacts did not transfer (future cost: 30-60 further minutes entering numbers, depending on use of laptop or iPhone, in addition to 15 minutes already spent finding and noting missing contacts)
Deleting type prefixes (e.g., TEL CELL) from phone numbers in a spreadsheet resulted in an irreversible conversion to a scientific format number (cost: 10 wasted minutes, plus future cost of 30-60 further minutes editing numbers in my phone, bewilderment, annoyance, mild anger, abusing colleagues’ company #2)
Had to set a wide range of synchronisation settings to restrict synchronisation to contacts (cost extra 10 minutes, initial disappointment and anxiety)
Being unable to blame Windows for anything (this time)!
By forming the list above, I have taken a position on what, in part, would count as poor usability. To form a judgement as to whether these costs were worthwhile, I also need to take a position on positive outcomes and experiences:
an opportunity to ask for, and receive, help from Facebook friends (realising some value of existing social capital)
a new email address gilbertcockton@... via an existing cloud computing account (future value unknown at time, but has since proved useful)
Discovered a semi-effective data path that transferred almost half of my contacts to my iPhone (saved: 30-60 minutes of manual entry, potential re-usable knowledge for future problem solving)
Learned about a nasty spreadsheet behaviour that could cause problems in the future unless I find out how to avoid it (future value potentially zero)
Learned about the Windows address book and how to upload new contacts as .csv files (very high future value - at the very least PC edits/updates are faster than iPhone, with very easy copy/paste from web and email)
Learned how to synchronise my new iPhone with my laptop via iTunes (extensive indubitable future value, repeatedly realised during the editing of this entry, including effortless extension to my recent new iPad)
Time to proof the previous draft of this entry and edit the next version (30 minutes of effective work during installs, restarts and uploads)
Sourced the main detailed example for this encyclopaedia entry (hopefully as valuable to you as a reader as to me as a writer:I’ve found it really helpful)
In many ways the question as to whether the combined devices and utilities were ‘usable’ has little value, as does any question about the extent of their combined usability. A more helpful question is whether the interaction was worthwhile, i.e., did the achieved resulting benefits justify the expended costs? Worth is a very useful English word that captures the relationship between costs and benefits: achieved benefits are (not) worth the incurred costs. Worth relates positive value to negative value, considering the balance of both, rather than, as in the case of poor usability, mostly or wholly focusing on negative factors.

Author/Copyright holder: Unknown (pending investigation). Copyright terms and licence: Unknown (pending investigation). See section "Exceptions" in the copyright terms below.
Figure 15.20: Usability Verdict: Not Guilty
So, did my resulting benefits justify my expended costs? My answer is yes, which is why I was satisfied at the time, and am more satisfied now as frustrations fade and potential future value has been steadily realised. Given the two or three usability problems encountered, and their associated costs, it is quite clear that the interaction could have been more worthwhile (increased value at lower costs), but this position is more clear cut than having to decide on the extent and severity of usability problems in isolation. The interaction would have been more worthwhile in the absence of usability problems (but I would not have this example). It would have also been more worthwhile if I’d already known in advance how to extract contacts from a Nokia backup file in a format where they could have been uploaded into the Windows address book of contacts. Still better, the utility suite that came with my phone could have had.cvs file import/export. Perhaps the best solution would be for phones to enable Windows to import contacts from them. Also, if I had used my previous laptop, the required phone utility suite was already installed and there should have been no initial connection problems. There were thus ways of reducing costs and increasing value that would not involve modifications to the software that I used, but would instead have replaced them all with one simple purpose built tool. None of the experienced usability problems would have been fixed. Once the complexity of the required data path is understood, it is clear that the best thing to do is to completely re-engineer it. Obliteration beats iteration here.

Author/Copyright holder: Unknown (pending investigation). Copyright terms and licence: Unknown (pending investigation). See section "Exceptions" in the copyright terms below.
Figure 15.21: At the end of the day, you have to look at the big picture
15.6.3 Usability is Only One Part of a BIG Interaction Design Picture
By considering usability within the broader context of experience and outcomes, many dilemmas associated with usability in isolation disappear. This generalises to human-centred design as a whole. In his book Change by Design, Tim Brown, CEO of IDEO, builds a compelling case for the human-centred practices of multi-disciplinary design teams. Even so, he acknowledges the lack of truly compelling stories that fully establish the importance of human-centred design to innovation, since these are undermined by examples of people regularly surmounting inconveniences (Brown 2009, pp.39-40), to which I have just added above. Through examples such as chaining bicycles to park benches, Brown illustrates worth in action: the benefit (security of bike) warrants the cost (finding a nearby suitable fixed structure to chain to). The problem with usability evaluations is that they typically focus on incurred costs without a balancing focus on achieved benefits. Brown returns to the issue of balance in his closing chapter, where design thinking is argued to achieve balance through its integrative nature (p.229).
Human-centred contributions to designs are just one set of inputs. Design success depends on effective integration of all its inputs. Outstanding design always overachieves, giving users/owners/sponsors far more than they were expecting. The best design is thus Balanced, Integrative and Generous - or plain BIG for short. Usability needs to fit into the big picture here.
Usability evaluation finds usage problems. These need to be understood holistically in the full design context before possible solutions can be proposed. Usability evaluation cannot function in isolation, at least, not without isolating the usability function. Since the early 90s, usability specialists have had a range of approaches to draw on, which, once properly adapted, configured and combined can provide highly valuable inputs to the iterative development of interaction designs. Yet we continue to experience interaction design flaws, such as lack of instructive actionable feedback on errors and problems, which can and should be eliminated. However, appropriate use of usability expertise is only one part of the answer. A complete solution requires better integration of usage evaluation into other design activities. Without such integration, usability practices will continue to be met often with disappointment, distrust, scepticism and a lack of appreciation in some technology development settings (Iivari 2005).
This sets us up for a third alternative definition of usability that steers a middle course between essentialism and relationalism:
“Usability is the extent of impact of negative user experiences and negative outcomes on the achievable worth of an interactive system. A usable system does not degrade or destroy achievable worth through excessive or unbearable usage costs.”
Usability can thus be understood as a major facet of user experience that can reduce achieved worth through adverse usage costs, but can only add to achieved worth through the iterative removal of usability problems. Usability improvements reduce usage costs, but cannot increase the value of usage experiences or outcomes. In this sense, usability has the same structural position as Herzberg’s (Herzberg 1966) hygiene factors in relation to his motivator factors.
15.6.4 From Hygiene Factors to Motivators

Author/Copyright holder: Courtesy of Office for Emergency Management. U.S. Office of War Information. Domestic Operations Branch. Bureau of Special Services. Copyright terms and licence: pd (Public Domain (information that is common property and contains no original authorship)).
Figure 15.22: Usability is a negative hygiene factor, not a positive motivator
Herzberg studied motivation at work, and distinguished positive motivators from negative hygiene factors in the workplace. Overt and sustained recognition at work is an example of a motivator factor, whereas inadequate salary is an example of a hygiene factor. Motivator factors can cause job satisfaction, whereas hygiene factors can cause dissatisfaction. Although referred to as Herzberg’s two-factor theory (after the two groups of factors), it spans three valences: positive, neutral and negative. The absence of motivators does not result in dissatisfaction, but in the (neutral) absence of (dis)satisfaction. Similarly, the absence of negative hygiene factors does not result in satisfaction, but in the (neutral) absence of (dis)satisfaction. Loss of a positive motivator thus results in being unsatisfied, whereas loss of an adverse hygiene factor results in being undissatisfied! Usability can thus be thought of as an overarching term for hygiene factors in user experience. Attending to poor usability can remove adverse demotivating hygiene factors, but it cannot introduce positive motivators.
Positive motivators can be thought of as the opposite pole of user experience to poor usability. Poor usability demotivates, but good usability does not motivate, only positive experiences and outcomes do. The problem with usability as originally conceived in isolation from other design concerns is that it only supports the identification and correction of defects, and not the identification and creation of positive qualities. Commercially, poor usability can make a product or service uncompetitive, but usability can only make it competitive relative to products or services with equal value but worse usability. Strategically, increasing value is a better proposition than reducing usage costs in any market where overall usability is ‘good enough’ across competitor products or services.
15.7 Future Direction for Usability Evaluation
Usage costs will always influence whether an interactive system is worthwhile or not. These costs will continue to be so high in some usage contexts that the achieved worth of an interactive system is degraded or even destroyed. For the most part, such situations are avoidable, and will only persist when design teams lack critical human-centred competences. While originally encountered in systems developed by software engineers, poor usability is now also linked to design decisions imposed by some visual designers, media producers, marketing ‘suits’, interfering managers, inept committees, or in-house amateurs. Usability experts will continue to be needed to fix their design disasters.
15.7.1 Putting Usability in its Place
In well directed design teams, there will not be enough work for a pure usability specialist. This is evidenced by a trend within the last decade of a broadening from usability to user experience expertise. User experience work focuses on both positive and negative value, both during usage and after it. A sole focus on negative aspects of interactive experiences is becoming rarer. Useful measures of usage are extending beyond the mostly cognitive problem measures of 1980s usability to include positive and negative affect, attitudes and values, e.g., fun, trust, and self-affirmation. The coupling between evaluation and design is being improved by user experience specialists with design competences. We might also include interaction designers with user experience competences, but no interaction designer worthy of the name should lack these! Competences in high-fidelity prototyping, scripting and even programming are allowing user experience specialists firstly to communicate human context insights through working prototypes (Rosenbaum 2008), and secondly to communicate possible design responses to user experience issues revealed in evaluations.
Many user experience professionals have also developed specific competences in areas such as brand experience, trust markers, search experience/optimisation, usable security and privacy, game experience, self and identity, and human values. We can see two trends here. The first involves complementing human-centred expertise with strong understandings of specific technologies such as search and security. The second involves a broadening of human-centred expertise to include business competences (e.g., branding) and humanistic psychological approaches (e.g., phenomenology, meaning and value). At the frontiers of user experience research, the potentials for exploiting insights from the humanities are being increasingly demonstrated (e.g., Bardzell 2011, Bardzell and Bardzell 2011, Blythe et al. 2011).
The extension of narrow usability expertise to broader user experience competences reduces the risk of inappropriate evaluation measures (Cockton 2007). However, each new user experience attribute introduces new measurement challenges, as do longer term measures associated with achieved value and persistent adverse consequences. A preference for psychometrically robust metrics must often be subordinated to the needs to measure specific value in the world, however and wherever it occurs. User experience work will thus increasingly require the development of custom evaluation instruments for experience attributes and worthwhile outcomes. Standard validated measures will continue to add value, but only if they are the right measures. There is however a strong trend towards custom instrumentation of digital technologies, above the level of server logs and low level system events (Rosenbaum 2008). Such custom instrumentation can extend beyond a single technology component to all critical user touch points in its embracing product-service ecosystem. For example, where problems arise with selecting, collecting, using and returning hired vans, it is essential to instrument the van hire depots, not the web site. Where measures relate directly to designed benefits and anticipated adverse interactions, this approach is known as direct worth instrumentation (Cockton 2008b).

Author/Copyright holder: Courtesy of Michael Sandberg. Copyright terms and licence: pd (Public Domain (information that is common property and contains no original authorship)).
Figure 15.23: The right instrumentation is crucial for worthwhile evaluation
Risks of inappropriate standard metrics arise when web site evaluations use the ready-to-hand measures of web server logs. What is easy to measure via a web server is rarely what is needed for meaningful relevant user experience evaluation. Thus researchers at Google (Rodden et al. 2010) have been developing a set of more relevant user experience (‘HEART’) measures to replace or complement existing log-friendly metrics (‘PULSE’ measures). The HEART measures are Happiness, Engagement, Adoption, Retention, and Task success. The PULSE measures are Page views, Uptime, Latency, Seven-day active users (i.e. count of unique users who used system at least once in last week), and Earnings. All PULSE measures are easy to make, but none are always relevant.
Earnings (sales) can of course be a simple and very effective measure for e-commerce as a measure of not one, but every, user interaction. As an example of the effectiveness of sales metrics, Sunderland University’s Alan Woolrych (see Figure 7) has contributed his expertise to commercial usability and user experience projects that have increased sales by seven digits (in UK sterling), increasing sales in one case by at least 30%. Improved usability has been only one re-design input here, albeit a vital one. Alan’s most successful collaborations involve marketing experts and lead business roles. Similar improvements have been recorded by collaborations involving user experience agencies and consultancies worldwide. However, the relative contributions of usability, positive user experience, business strategy and marketing expertise are not clear, and in some ways irrelevant. The key point is that successful e-commerce sites require all such inputs to be co-ordinated throughout projects.
There are no successful digital technologies without what might be regarded as usability flaws. Some appear to have severe flaws, and are yet highly successful for many users. Usability’s poor reputation in some quarters could well be due to its focus on the negative at the expense of the positive. What matters is the resulting balance of worth as judged by all relevant stakeholders, i.e., not just users, but also, for example, projects’ sponsors, service provision staff, service management, politicians, parents, business partners, and even the general public.

Author/Copyright holder: Microsoft Research in Cambridge and Abigail Sellen, Shahram Izadi, Richard Harper, and Rachel Eardley. Copyright terms and licence: All Rights Reserved. Reproduced with permission. See section "Exceptions" in the copyright terms below.
Figure 15.24: Evaluation of the Whereabouts Clock revealed unexpected benefits

Author/Copyright holder: Microsoft Research in Cambridge and Abigail Sellen, Shahram Izadi, Richard Harper, and Rachel Eardley. Copyright terms and licence: All Rights Reserved. Reproduced with permission. See section "Exceptions" in the copyright terms below.
Figure 15.25: The Whereabouts Clock in its usage context
Evaluation needs to focus on both positives and negatives. The latter need to be identified and assessed for their impact on achieved worth. Where there are unacceptable adverse impacts, re-design and further evaluation is needed to confirm that unintended negative experiences and/or outcomes have been ‘designed out’. However, evaluation misses endless opportunities when it fails to identify unintended positives experiences and/or outcomes. Probe studies have proved to be highly effective here, identifying positive appropriative use that was completely unanticipated by design teams (e.g., Brown et al. 2007, Gaver et al. 2008). It is refreshing to encounter evaluation approaches that identify unexpected successes as well as unwanted failures. For example, the evaluation of the Whereabouts Clock (Brown et al. 2007) revealed one boy’s comfort at seeing his separated family symbolically united on the clock’s face.
Designers and developers are more likely to view evaluation positively if it is not overwhelmingly negative. Also, this spares evaluators from ritually starting their reports with a ‘few really good points about the design’ before switching into a main body of negative problems. There should always be genuine significant positive experiences and outcomes to report.
Evaluation becomes more complicated once positive and negative phenomena need to be balanced against each other across multiple stakeholders. Worth has been explored as an umbrella concept to cover all interactions between positive and negative phenomena (Cockton 2006). As well as requiring novel custom evaluation measures, this also requires ways to understand the achievement and loss of worth. There have been some promising results here with novel approaches such as worth maps (Cockton et al. 2009a, Cockton et al. 2009b, Otero and José 2009). Worth maps can give greater prominence to system attributes while simultaneously relating them to contextual factors of human experiences and outcomes. Evaluation can focus on worth map elements (system attributes, user experience attributes, usage outcomes) or on the connections between them, offering a practical resource for moving beyond tensions between essentialist and relational positions on software quality.
Worth-focused evaluation remains underdeveloped, but will focus predominantly on outcomes unless experiential values dominate design purpose (as in many games). Where experiential values are not to the fore, detailed evaluation of user interactions may not be worthwhile if products and services have been shown to deliver or generously donate value. Evaluation of usage could increasingly become a relatively infrequent diagnostic tool to pinpoint where and why worth is being degraded or destroyed. Such a strategic focus is essential now that we have new data collection instruments such as web logs and eye tracking that gather massive amounts of data. Such new weapons in the evaluation arsenal must be carefully aimed. A 12-bore shotgun scattershot approach cannot be worthwhile for any system of realistic complexity. This is particularly the case when, as in my personal example of phone contacts transfer, whole product ecologies (Forlizzi 2008) must be evaluated, and not component parts in isolation. When usage within such product ecologies here is mobile, intermittent and moves through diverse social contexts, it becomes even more unrealistic to evaluate every second of user interaction.
In the future, usability evaluation will be put in its place. User advocates will not be given free rein to berate and scold. They will become integral parts of design teams with Balanced, Integrated and Generous (BIG!) design practices. It’s time for all the stragglers in usability evaluation to catch up with the BIG boys and girls. Moaning on the margins about being ignored and undervalued is no longer an option. Usability must find its proper place within interaction design, as an essential part of the team, but rarely King of the Hill. The reward is that usability work could become much more rewarding and less fraught. That has got to be worthwhile for all concerned.

Author/Copyright holder: Courtesy of Tety. Copyright terms and licence: CC-Att-2 (Creative Commons Attribution 2.0 Unported).

Author/Copyright holder: Courtesy of Joel Rogers. Copyright terms and licence: pd (Public Domain (information that is common property and contains no original authorship)).
Figure 15.26 A-B: From Solo Specialist to Team Member: User Experience as an integrated part of design teams
15.8 Where to learn more
HCI Remixed (Erickson and McDonald 2008) is an excellent collection of short essays on classic HCI books and papers, plus other writing that has influenced leading HCI researchers. It contains a short essay (Cockton 2008a) on the Whiteside et al. (1988) classic, and many more of interest.
There is a short account of BIG Design in
Cockton, G. Design: BIG and Clever, Interfaces Magazine, 87, British Interaction Group, ISSN 1351-119X 2011, 5-7
Sears’ and Jacko’s HCI Handbook (Sears and Jacko 2007) is a very comprehensive collection of detailed chapters on key HCI topics. The 3rd edition will be published in 2012. There are chapters on user testing, inspection methods, model-based methods and other usability evaluation topics.
Darryn Lavery prepared a set of tutorial materials on inspection methods in the 1990s that are still available:
Lavery, D., Cockton, G., and Atkinson, M. P. 1996. Heuristic Evaluation: Usability Evaluation Materials, Technical Report TR-1996-15, University of Glasgow. Accessed 15/9/11 at http://www.dcs.gla.ac.uk/asp/materials/HE_1.0/materials.pdf
Lavery, D., Cockton, G., and Atkinson, M. P. 1996. Heuristic Evaluation for Software Visualisation: Usability Evaluation Materials, Technical Report TR-1996-16, University of Glasgow, 1996. Accessed 15/9/11 at http://www.dcs.gla.ac.uk/asp/materials/SVHE_1.0/materials.pdf
Lavery, D., Cockton, G., and Atkinson, M. P. 1996. Cognitive Dimensions: Usability Evaluation Materials, Technical Report TR-1996-17, University of Glasgow. Accessed 15/9/11 at http://www.dcs.gla.ac.uk/asp/materials/CD_1.0/materials.rtf
Lavery, D., and Cockton, G. 1997. Cognitive Walkthrough: Usability Evaluation Materials, Technical Report TR-1997-20, Department of Computing Science, University of Glasgow. Edited version available 15/9/11 as http://www.dcs.gla.ac.uk/~pdg/teaching/hci3/cwk/cwk.html
Europe’s COST programme has funded two large research networks on evaluation and design methods. The MAUSE project (COST Action 294, 2004-2009) focused on maturing usability evaluation methods. The TwinTide project (COST Action IC0904, 2009-2013) has a broader focus on design and evaluation methods for interactive software. There are several workshop proceedings on the MAUSE web site (www.cost294.org), including the final reports, as well as many publications by network members on the associated MAUSE digital library. The TwinTide web site (www.twintide.org) is adding new resources as this new project progresses.
The Usability Professionals Association, UPA, have developed some excellent resources, especially their open access on-line Journal of Usability Studies. Their Body of Knowledge project, BOK, also has created a collection of resources on evaluation methods that complement the method directory prepared by MAUSE WG1. Practically minded readers may prefer BOK content over more academically oriented research publications.
Jakob Nielsen has developed and championed discount evaluation methods for over two decades. He co-developed Heuristic Evaluation with Rolf Mohlich. Jakob’s www.useit.com web site contains many useful resources, but some need updating to reflect some major developments in usability evaluation and interaction design over the last decade. For example, in the final version of his heuristics some known issues with Heuristic Evaluation are not covered. Even so, the critical reader will find many valuable resources on www.useit.com. Hornbæk (2010) is a very good source of critical perspectives on usability engineering, and should ideally be read alongside browsing within www.useit.com.
The American Association for Computing Machinery (ACM) sponsors many key HCI conferences through its SIGCHI special interest group. The annual CHI (Computer-Human Interaction) conference is an excellent source for research papers. There is no specialist ACM conference with a focus on usability evaluation, but the SIGCHI DIS (Designing Interactive Systems) conference proceedings and the DUX (Designing for User Experiences) conference proceedings do contain some valuable research papers, as does the SIGCHI CSCW conference series. The SIGCHI UIST conference (Symposium on User Interface Software and Technology) often includes papers with useful experimental evaluations of innovative interactive components and design parameters. All ACM conference proceedings can be accessed via the ACM Digital Library. Relevant non ACM conferences include UPA (The Usability Professionals' Association international conference), ECCE (the European Conference on Cognitive Ergonomics), Ubicomp (International Conference on Ubiquitous Computing), INTERACT (the International Federation for Information Processing Conference on Human-Computer Interaction) and the British HCI Conference series. UPA has a specific practitioner focus on usability evaluation. Most HCI publications are indexed on www.hcibib.org. In November 2011, a search for usability evaluation found almost 1700 publications.
15.9 Acknowledgements
I have been immensely fortunate to have collaborated with some of the most innovative researchers and practitioners in usability evaluation, despite having no serious interest in usability in my first decade of work in Interaction Design and HCI!
One of my first PhD students at Glasgow University, Darryn Lavery, changed this through his struggle with what I had thought was going to be a straightforward PhD on innovative inspection methods. Darryn exposed a series of serious fundamental problems with initial HCI thinking on usability evaluation. He laid the foundations for over a decade of rigorous critical research through his development of conceptual critiques (Lavery et al. 1997), problem report formats (Lavery and Cockton 1997), and problem extraction methodologies (Cockton and Lavery 1999). From 1998, Alan Woolrych, Darryn Lavery (to 2000), myself and colleagues at Sunderland University built on these foundations in a series of studies that exposed the impact of specific resources on the quality of usability work (e.g., Cockton et al. 2004), as well as demonstrating the effectiveness of these new understandings in Alan’s commercial and e-government consultancies. Research tactics from our studies were also used to good effect from 2005-2009 by members of WG2 of COST Action 294 (MAUSE - see Where to learn more above), resulting in a new understanding of evaluation methods as usability work that adapts, configures and combines methods (Cockton and Woolrych 2009). COST’s support for MAUSE and the the follow on TwinTwide Action (Where to learn more, below) has been invaluable for maintaining a strong focus on usability and human-centred design methods in Europe. Within Twintide, Alan Woolrych, Kasper Hornbæk, Erik Frøkjær and I have applied results from MAUSE to the analysis of Inspection Methods (Cockton et al. 2012), and more broadly within the broader context of usability work (Woolrych et al. 2011).
Nigel Bevan, a regular contributor to MAUSE and TwinTide activities has provided helpful advice, especially on international standards. Nigel is one of many distinguished practitioners who have generously shared their expertise and given me feedback on my research. At the risk of omission and in no particular order, I would particularly like to acknowledge generous sharing of knowledge of and insights on usability and emerging evaluation practices by Tom Hewett, Fred Hansen, Jonathan Earthy, Robin Jeffries, Jakob Nielsen, Terry Roberts, Bronwyn Taylor, Ian McClelland, Ken Dye, David Caulton, Wai On Lee, Mary Czerwinski, Dennis Wixon, Arnie Lund, Gaynor Williams, Lynne Coventry, Jared Spool, Carolyn Snyder, Will Schroeder, John Rieman, Giles Colborne, David Roberts, Paul Englefield, Amanda Prail, Rolf Mohlich, Elizabeth Dykstra-Erickson, Catriona Campbell, Manfred Tscheligi, Verena Giller, Regina Bernhaupt, Lucas Noldus, Bonnie John, Susan Dray, William Hudson, Stephanie Rosenbaum, Bill Buxton, Marc Hassenzahl, Carol Barnum, William Hudson, Bill Gaver, Abigail Sellen, Jofish Kaye, Tobias Uldall-Espersen, John Bowers and Elizabeth Buie. My apologies to anyone who I have left out!
15.10 References
Bardzell, Jeffrey (2011): Interaction criticism: An introduction to the practice. In Interacting with Computers, 23 (6) pp. 604-621
Bardzell, Jeffrey (2009): Interaction criticism and aesthetics. In: Proceedings of ACM CHI 2009 Conference on Human Factors in Computing Systems 2009. pp. 2357-2366
Bardzell, Shaowen and Bardzell, Jeffrey (2011): Towards a feminist HCI methodology: social science, feminism, and HCI. In: Proceedings of ACM CHI 2011 Conference on Human Factors in Computing Systems 2011. pp. 675-684
Bellamy, Rachel, John, Bonnie E. and Kogan, Sandra (2011): Deploying CogTool: integrating quantitative usability assessment into real-world software development. In: Proceeding of the 33rd international conference on Software engineering 2011. pp. 691-700
Blythe, Mark, Petrie, Helen and Clark, John A. (2011): F for fake: four studies on how we fall for phish. In:Proceedings of ACM CHI 2011 Conference on Human Factors in Computing Systems 2011. pp. 3469-3478
Brown, Tim (2009): Change by Design: How Design Thinking Transforms Organizations and Inspires Innovation.HarperBusiness
Brown, Barry A. T., Taylor, Alex S., Izadi, Shahram, Sellen, Abigail, Kaye, Joseph Jofish and Eardley, Rachel (2007): Locating Family Values: A Field Trial of the Whereabouts Clock. In: Krumm, John, Abowd, Gregory D.,Seneviratne, Aruna and Strang, Thomas (eds.) UbiComp 2007 Ubiquitous Computing - 9th International Conference September 16-19, 2007, Innsbruck, Austria. pp. 354-371
Card, Stuart K., Moran, Thomas P. and Newell, Allen (1980): The keystroke-level model for user performance with interactive systems. In Communications of the ACM, 23 pp. 396-410
Cockton, Gilbert (2006): Designing worth is worth designing. In: Proceedings of the Fourth Nordic Conference on Human-Computer Interaction 2006. pp. 165-174
Cockton, Gilbert (2007): Some Experience! Some Evolution. In: Erickson, Thomas and McDonald, David W. (eds.). "HCI Remixed: Reflections on Works That Have Influenced the HCI Community". The MIT Presspp. 215-219
Cockton, Gilbert (2004): Value-centred HCI. In: Proceedings of the Third Nordic Conference on Human-Computer Interaction October 23-27, 2004, Tampere, Finland. pp. 149-160
Cockton, Gilbert (2008): Load while Aiming; Hit? (invited keynote). In: Brau, Henning (ed.). "Usability Professionals 2008 Conference". pp. 17-22
Cockton, Gilbert and Lavery, Darryn (1999): A Framework for Usability Problem Extraction. In: Angela.Sasse, M. andJohnson, Chris (eds.) Proceedings of Interact 99 1999, Edinburgh.
Cockton, Gilbert and Woolrych, Alan (2009): A. Comparing UEMs: Strategies and Implementation, Final Report of COST 294 Working Group 2. In: Law, Effie Lai-Chong, Scapin, Dominique, Cockton, Gilbert, Springett, Mark,Stary, C. and Winckler, Marco (eds.). "Maturation of Usability Evaluation Methods: Retrospect and Prospect: Final Reports of COST294-MAUSE Working Groups".
Cockton, Gilbert, Woolrych, Alan, Hornbæk, Kasper and Frøkjær, Erik (2012): Inspection-based methods. In: Sears, Andrew and Jacko, Julie A. (eds.). "The Human-Computer Interaction Handbook: Fundamentals, Evolving Technologies and Emerging Applications, Third Edition". pp. 1275-1293
Cockton, Gilbert, Woolrych, Alan and Hindmarch, Mark (2004): Reconditioned merchandise: extended structured report formats in usability inspection. In: Dykstra-Erickson, Elizabeth and Tscheligi, Manfred (eds.) Extended abstracts of the 2004 Conference on Human Factors in Computing Systems, CHI 2004, Vienna, Austria, April 24 - 29, 2004 2004. pp. 1433-1436
Cockton, Gilbert, Kujala, Sari, Nurkka, Piia and Hölttä, Taneli (2009): Supporting Worth Mapping with Sentence Completion. In: Gross, Tom, Gulliksen, Jan, Kotze, Paula, Oestreicher, Lars, Palanque, Philippe A., Prates, Raquel Oliveira and Winckler, Marco (eds.) Human-Computer Interaction - INTERACT 2009, 12th IFIP TC 13 International Conference, Uppsala, Sweden, August 24-28, 2009, Proceedings, Part II 2009. pp. 566-581
Cockton, Gilbert, Kirk, Dave, Sellen, Abigail and Banks, Richard (2009): Evolving and augmenting worth mapping for family archives. In: Proceedings of the HCI09 Conference on People and Computers XXIII 2009. pp. 329-338
Dumas, Joseph S. and Fox, Jean E. (2007): Usability Testing: Current Practice and Future Directions. In: Sears, Andrew and Jacko, Julie A. (eds.). "The Human-Computer Interaction Handbook: Fundamentals, Evolving Technologies and Emerging Applications, Second Edition (Human Factors and Ergonomics)". CRC Presspp. 1129-1150
Dumas, Joseph S. and Redish, Janice C. (1993): A Practical Guide to Usability Testing. Norwood, NJ, Intellect
Erickson, Thomas and McDonald, David W. (2008): HCI Remixed: Reflections on Works that Have Influenced the HCI Community. Cambridge, Massachusetts, MIT Press
Forlizzi, Jodi (2008): The product ecology: Understanding social product use and supporting design culture. InInternational Journal of Design, 2 (1) pp. 11-20
Gaver, William W., Boucher, Andy, Law, Andy, Pennington, Sarah, Bowers, John, Beaver, Jacob, Humble, Jan,Kerridge, Tobie, Villar, Nicholas and Wilkie, Alex (2008): Threshold devices: looking out from the home. In:Proceedings of ACM CHI 2008 Conference on Human Factors in Computing Systems April 5-10, 2008. pp. 1429-1438
Gray, Wayne D. and Salzman, Marilyn C. (1998): Damaged Merchandise? A Review of Experiments That Compare Usability Evaluation Methods. In Human-Computer Interaction, 13 (3) pp. 203-261
Harper, Richard, Rodden, Tom, Rogers, Yvonne and Sellen, Abigail (2008): Being Human: Human Computer Interaction in 2020. Microsoft Research Ltd
Hertzum, Morten and Jacobsen, Niels Ebbe (2001): The Evaluator Effect: A Chilling Fact About Usability Evaluation Methods. In International Journal of Human-Computer Interaction, 13 (4) pp. 421-443
Herzberg, Frederick (1966): Work and the Nature of Man.
Herzberg, Frederick (1973): Work and the Nature of Man. Signet
Hornbæk, Kasper (2010): Dogmas in the assessment of usability evaluation methods. In Behaviour and Information Technology, 29 (1) pp. 97-111
Iivari, N. (2005): Usability Specialists - 'Mommy Mob', 'Realistic Humanists' or 'Staid Researchers'? An Analysis of Usability Work in the Software Product Development. In: Proceedings of IFIP INTERACT05: Human-Computer Interaction 2005. pp. 418-430
International Standards Association (1991). ISO/IEC 9126: Software engineering - Product quality. Retrieved 1 December 2011 from International Standards Association: http://en.wikipedia.org/wiki/ISO/IEC_9126
International Standards Association (1998). ISO 9241-11: Ergonomic requirements for office work with visual display terminals (VDTs) -- Part 11: Guidance on usability. Retrieved 1 December 2011 from International Standards Association: http://en.wikipedia.org/wiki/ISO/IEC_9126
International Standards Association (2001). ISO/IEC 9126-1:2001 Software engineering - Product quality - Part 1: Quality model,. Retrieved 1 December 2011 from International Standards Association: http://www.iso.org/iso/iso_catalogue/catalogue_tc/...
International Standards Association (2004). ISO/IEC TR 9126-4:2004 Software engineering -- Product quality -- Part 4: Quality in use metrics. Retrieved 1 December 2011 from International Standards Association: http://www.iso.org/iso/iso_catalogue/catalogue_tc/...
International Standards Association (2011). ISO/IEC 25010 Systems and software engineering -- Systems and software Quality Requirements and Evaluation (SQuaRE) -- System and software quality models. Retrieved 1 December 2011 from International Standards Association: http://www.iso.org/iso/catalogue_detail.htm?csnumb...
John, Bonnie E. and Kieras, David E. (1996): Using GOMS for User Interface Design and Evaluation: Which Technique?. In ACM Transactions on Computer-Human Interaction, 3 (4) pp. 287-319
Landauer, Thomas K. (1996): The Trouble with Computers: Usefulness, Usability, and Productivity. The MIT Press
Lavery, Darryn, Cockton, Gilbert and Atklnson, Malcolm P. (1997): Comparison of Evaluation Methods Using Structured Usability Problem Reports. In Behaviour and Information Technology, 16 (4) pp. 246-266
Law, Effie Lai-Chong, Hvanberg, Ebba, Cockton, Gilbert, Palanque, Philippe A., Scapin, Dominique L., Springett, Mark, Stary, Christian and Vanderdonckt, Jean M. (2005): Towards the maturation of IT usability evaluation (MAUSE). In: Costabile, Maria Francesca and Paterno, Fabio (eds.). "Human-computer interaction: INTERACT 2005: IFIP TC13 international conference: proceedings. Lecture Notes in Computer Science. (3585)". pp. 1134-1137
Nielsen, Jakob (1994): Enhancing the explanatory power of usability heuristics. In: Plaisant, Catherine (ed.)Conference on Human Factors in Computing Systems, CHI 1994, Boston, Massachusetts, USA, April 24-28, 1994, Conference Companion 1994. p. 210
Otero, Nuno and José, Rui (2009): Worth and Human Values at the Centre of Designing Situated Digital Public Displays. In IJAPUC, 1 (4) pp. 1-13
Pew, Richard W. (2002): Evolution of human-computer interaction: from Memex to Bluetooth and beyond. In:Sears, Andrew and Jacko, Julie A. (eds.). "The Human-Computer Interaction Handbook: Fundamentals, Evolving Technologies and Emerging Applications (Human Factors and Ergonomics)". Lawrence Erlbaumpp. 1-17
Rodden, Kerry, Hutchinson, Hilary and Fu, Xin (2010): Measuring the user experience on a large scale: user-centered metrics for web applications. In: Proceedings of ACM CHI 2010 Conference on Human Factors in Computing Systems 2010. pp. 2395-2398
Rogers, Yvonne, Bannon, Liam and Button, Graham (1994): Rethinking theoretical frameworks for HCI: A Review. In ACM SIGCHI Bulletin, 26 (1) pp. 28-30
Rosenbaum, Stephanie (2008): The Future of Usability Evaluation : Increasing Impact on Value. In: Law, Effie Lai-Chong, Hvannberg, Ebba Thora and Cockton, Gilbert (eds.). "Maturing Usability". Springerpp. 344-378
Rosenbaum, Stephanie, Rohn, Janice Anne and Humburg, Judee (2000): A Toolkit for Strategic Usability: Results from Workshops, Panels, and Surveys. In: Turner, Thea, Szwillus, Gerd, Czerwinski, Mary, Peterno, Fabio andPemberton, Steven (eds.) Proceedings of the ACM CHI 2000 Human Factors in Computing Systems ConferenceApril 1-6, 2000, The Hague, The Netherlands. pp. 337-344
Salvucci, Dario D. (2009): Rapid prototyping and evaluation of in-vehicle interfaces. In ACM Transactions on Computer-Human Interaction, 16 (2) p. 9
Sears, Andrew and Jacko, Julie A. (2007): The Human-Computer Interaction Handbook: Fundamentals, Evolving Technologies and Emerging Applications (2nd Edition). Lawrence Erlbaum Associates
Sengers, Phoebe and Gaver, William (2006): Staying open to interpretation: engaging multiple meanings in design and evaluation. In: Proceedings of DIS06: Designing Interactive Systems: Processes, Practices, Methods, & Techniques 2006. pp. 99-108
Shneiderman, Ben (1986): No members, no officers, no dues: A ten year history of the software psychology society. In ACM SIGCHI Bulletin, 18 (2) pp. 14-16
Smith, Sidney L. and Mosier, Jane N. (1986). GUIDELINES FOR DESIGNING USER INTERFACE SOFTWARE, The MITRE Corporation, Bedford, Massachusetts, USA, Prepared for Deputy Commander for Development Plans, and Support Systems, Electronic Systems Division, AFSC, United States Air Force, Hanscom Air Force B.
Venturi, Giorgio, Troost, Jimmy and Jokela, Timo (2006): People, Organizations, and Processes: An Inquiry into the Adoption of User-Centered Design in Industry. In International Journal of Human-Computer Interaction, 21 (2) pp. 219-238
Wasserman, Anthony I. (1973): The design of 'idiot-proof' interactive programs. In: Proceedings of the June 4-8, 1973, national computer conference and exposition 1973. pp. m34-m38
Whiteside, John, Bennett, John and Holtzblatt, Karen (1988): Usability Engineering: Our experience and Evolution. In: Helander, Martin and Prabhu, Prasad V. (eds.). "Handbook of human-computer interactio". pp. 791-817
Wilson, Chauncey (1999). Severity Scale for Classifying Usability Problems. Retrieved 1 December 2011 from The Usability SIG Newsletter: http://www.stcsig.org/Usability/newsletter/9904-se...
Woolrych, Alan, Hornbæk, Kasper, Frøkjær, Erik and Cockton, Gilbert (2011): Ingredients and Meals Rather Than Recipes: a Proposal for Research That Does Not Treat Usability Evaluation Methods As Indivisible Wholes. InInternational Journal of Human-Computer Interaction, 99999 (1) pp. 1-1