Your constantly-updated definition of Neural Networks (NN) and
collection of videos and articles. Be a conversation starter: Share this page and inspire others!
97shares
What are Neural Networks (NN)?
ShowHide
video transcript
Transcript loading…
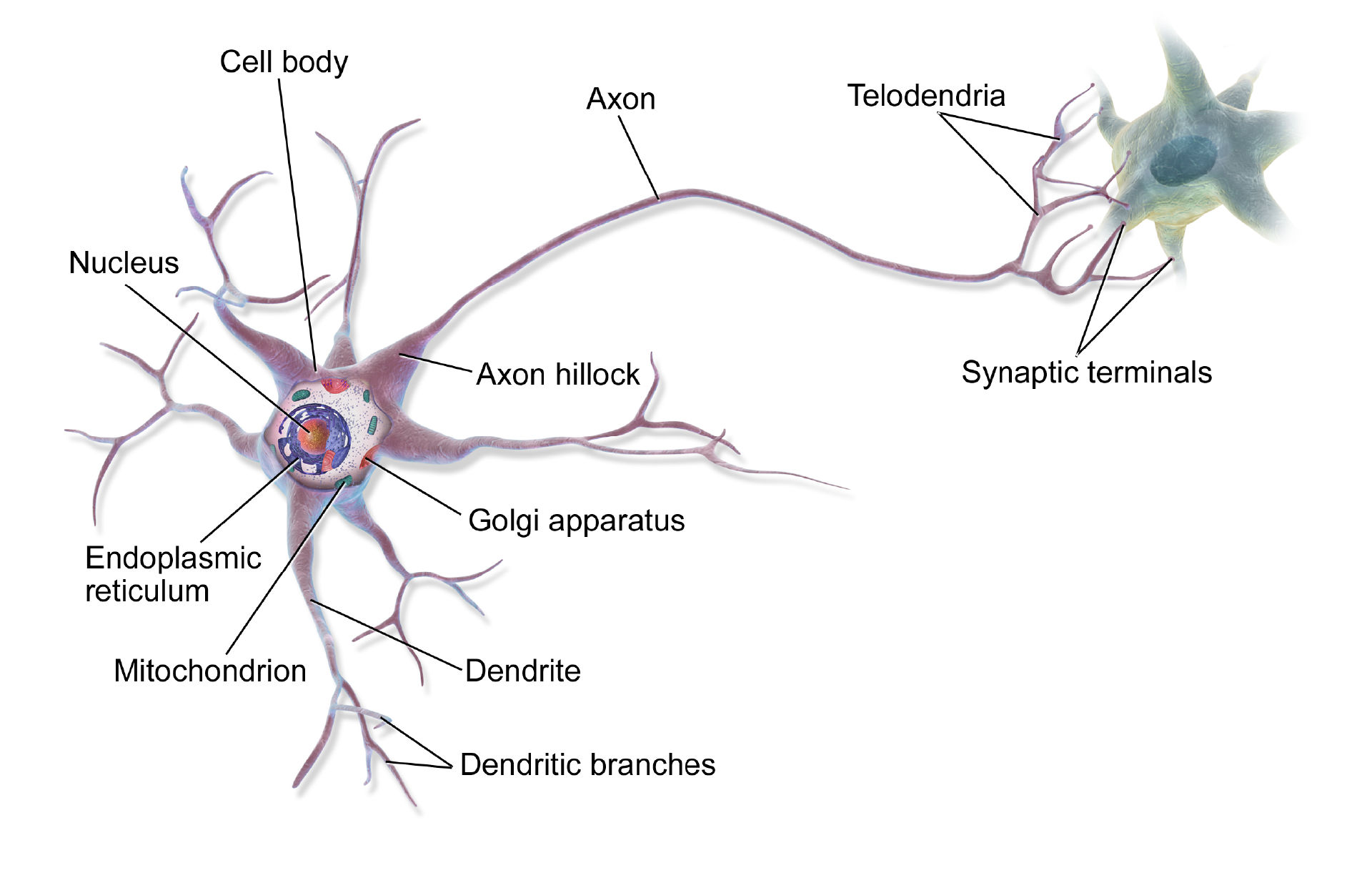
Neural networks are a type of artificial intelligence that can learn from data and perform various tasks, such as recognizing faces, translating languages, playing games, and more. Neural networks are inspired by the structure and function of the human brain, which consists of billions of interconnected cells called neurons. Neural networks are made up of layers of artificial neurons that process and transmit information between each other. Each neuron has a weight and a threshold that determine how much it contributes to the output of the next layer. Neural networks can be trained using different algorithms, such as backpropagation, gradient descent, or genetic algorithms. Neural networks can also have different architectures, such as feedforward, recurrent, convolutional, or generative adversarial networks. Neural networks are powerful tools for artificial intelligence because they can adapt to new data and situations, generalize from previous examples, and discover hidden patterns and features in the data.
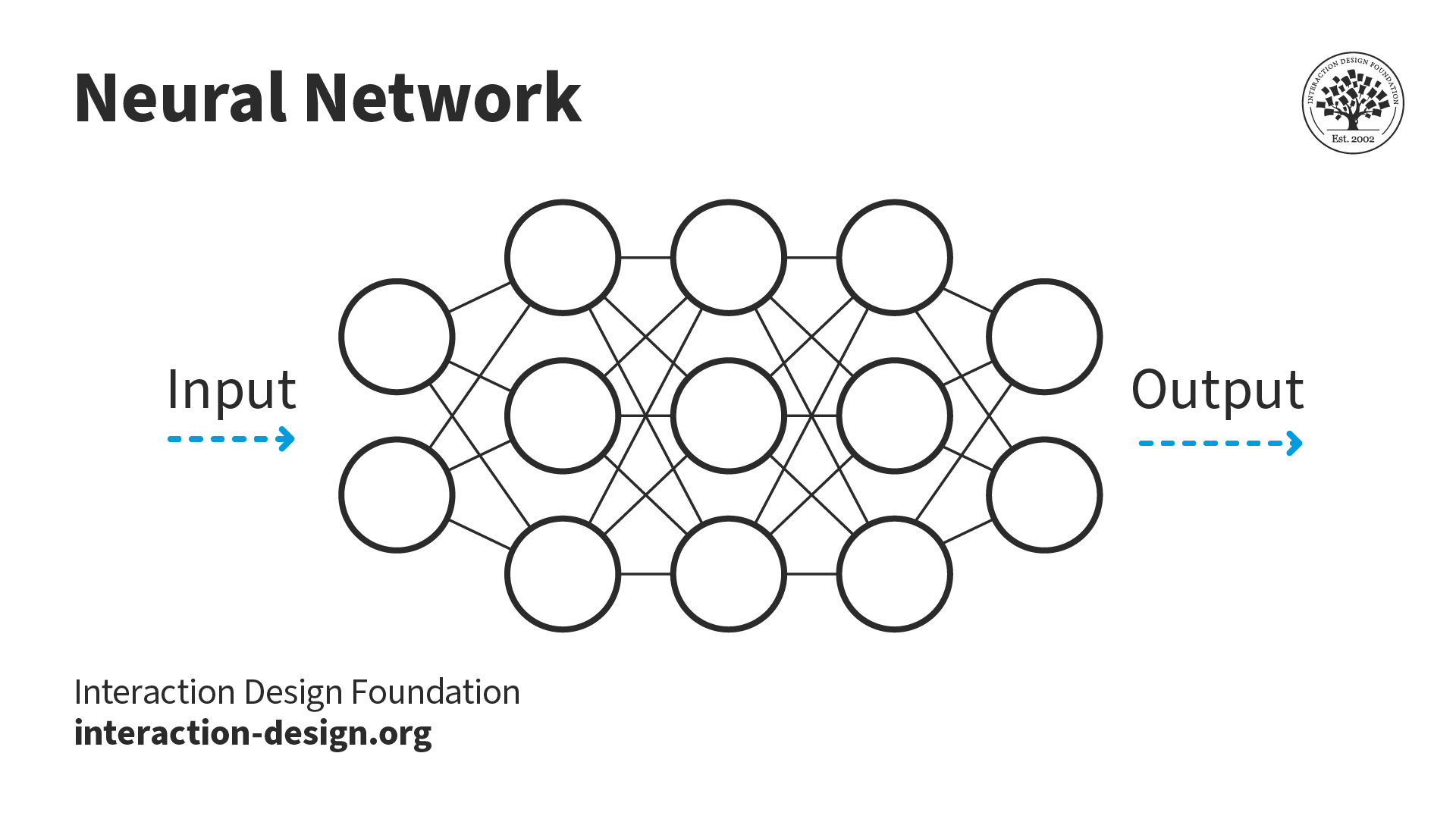
Neural networks consist of input and output layers (far left and right) as well as intermediary hidden layers.
1957: Frank Rosenblatt developed the perceptron, a single-layer neural network that can learn to classify linearly separable patterns.
1969: Marvin Minsky and Seymour Papert publish a book called Perceptrons, which shows the limitations of single-layer neural networks and discourages further research.
1970: Seppo Linnainmaa introduces the backpropagation algorithm, which can efficiently compute the gradients of a multi-layer neural network.
1980: Kunihiko Fukushima proposes the neocognitron, a hierarchical neural network that can recognize handwritten digits and other patterns.
1982: John Hopfield introduces the Hopfield network, a recurrent neural network that can store and retrieve patterns as attractors of its dynamics.
1986: David Rumelhart, Geoffrey Hinton, and Ronald Williams popularize the backpropagation algorithm and demonstrate its applications to various problems such as speech recognition, computer vision, and natural language processing.
1990s: Neural networks face a decline in interest due to the emergence of other machine learning methods, such as support vector machines and the lack of computational resources and data to train large-scale models.
2006: Geoffrey Hinton, Yann LeCun, Yoshua Bengio, and others revive the interest in deep learning by showing that pre-training neural networks layer by layer can overcome the problem of vanishing gradients and improve their performance.
2012: Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton win the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) by using a deep convolutional neural network (CNN) that achieves a significant improvement over previous methods.
2014: Ian Goodfellow, Yoshua Bengio, and Aaron Courville publish a book called Deep Learning, which provides a comprehensive overview of the theory and practice of deep learning.
2015: Google DeepMind develops AlphaGo, a deep reinforcement learning system that defeats the world champion of Go, a complex board game that requires human intuition and creativity.
2016: Google Translate launches a new version based on neural machine translation (NMT), which uses an encoder-decoder architecture with attention mechanisms to translate sentences between different languages.
2017: Facebook develops DeepFace, a deep face recognition system that achieves near-human accuracy on the Labeled Faces in the Wild (LFW) dataset.
2018: OpenAI develops GPT, a large-scale generative pre-trained transformer model that can generate coherent and diverse text on various topics.
2019: Google develops BERT, a bidirectional encoder representation from transformers model that achieves state-of-the-art results on several natural language understanding tasks such as question answering, sentiment analysis, and named entity recognition.
Applications of Neural Networks
Neural networks have many applications in various domains, such as:
Image recognition: Neural networks can recognize and classify objects, faces, scenes, and activities in images. For example, Facebook uses a deep face recognition system called DeepFace that achieves near-human accuracy on the Labeled Faces in the Wild (LFW) dataset.
Speech recognition: Neural networks can convert spoken words into text or commands. For example, Google Assistant uses a neural network to understand natural language queries and provide relevant answers.
Machine translation: Neural networks can translate sentences or documents between different languages. For example, Google Translate uses a neural machine translation (NMT) system with an encoder-decoder architecture with attention mechanisms to translate sentences between different languages.
Screenshot of Google Translate. This example used to appear in some printed phrasebooks!
Google Translate, Fair Use
Natural language processing: Neural networks can analyze and generate natural language texts for various purposes, such as sentiment analysis, question answering, text summarization, and text generation. For example, OpenAI developed GPT, a large-scale generative pre-trained transformer model that can generate coherent and diverse text on various topics in response to AI prompts.
Medical diagnosis: Neural networks can diagnose diseases or conditions based on symptoms, tests, or images. For example, IBM Watson uses a neural network to analyze medical records and provide diagnosis and treatment recommendations for cancer patients.
Financial forecasting: Neural networks can predict future trends or outcomes based on historical data or market signals. For example, JPMorgan Chase uses a neural network to forecast the stock market movements and optimize its trading strategies.
Quality control: Neural networks can detect defects or anomalies in products or processes based on visual inspection or sensor data. For example, Tesla uses a neural network to monitor the quality of its electric vehicles and identify any issues or faults.
Gaming: Neural networks can play games or simulate realistic environments based on rules or rewards. For example, Google DeepMind developed AlphaGo, a deep reinforcement learning system that defeated the world champion of Go, a complex board game that requires human intuition and creativity.
Screenshot of AlphaGo versus Lee Sedol in 2016. AlphaGo won four out of the five games played.
CC BY-SA 4.0 ShareAlike (https://creativecommons.org/licenses/by-sa/4.0/)
Future of Neural Networks in Deep Learning
Some of the possible directions for the future of neural networks in deep learning are:
Neuroevolution: This is the application of evolutionary algorithms (EAs) to the configuration and optimization of neural networks. EAs are a type of optimization technique that mimic the process of natural selection and evolution. Neuroevolution can help to find optimal neural network architectures, hyperparameters, weights, and activation functions without human intervention.
Symbolic AI: This integrates symbolic artificial intelligence (AI) with neural networks. Symbolic AI is a type of AI that uses logic, rules, symbols, and knowledge representation to perform reasoning and inference. Symbolic AI can help to overcome some of the limitations of neural networks, such as explainability, generalization, robustness, and causality. Some researchers argue that neural networks will eventually move past their shortcomings without help from symbolic AI, but rather by developing better architectures and learning algorithms.
Generative models: These neural networks can generate new data or content based on existing data or content. Generative models can be used for various purposes, such as data augmentation, image synthesis, text generation, style transfer, etc. Generative adversarial networks (GANs) are a popular type of generative model that use two competing neural networks: a generator that tries to create realistic data and a discriminator that tries to distinguish between real and fake data.
Learn More about Neural Networks
Worried AI will replace you? It won't just yet. But a designer using AI might. Take the course, AI for Designers, to master how to collaborate with AI, rather than competing against it. You’ll gain practical, future-proof skills to integrate AI into your workflow and design for AI-powered products.
Questions about Neural Networks
What is a neural network?
A neural network is a computer system that tries to imitate how the human brain works. It consists of many artificial neurons connected to each other and can process information by learning from data. A neural network can perform tasks such as speech recognition, image analysis, and adaptive control.
How do neural networks work?
Neural networks work by simulating the way the human brain processes information. They consist of many artificial neurons connected by weights and biases, determining how much influence one neuron has on another. Neural networks can learn from data by adjusting their weights and biases based on the error between their output and the desired output.
How do neural networks learn?
Neural networks learn by changing their weights and biases based on the error between their output and the desired output. This process is called backpropagation. Neural networks use different loss functions to measure the error. They also use different optimization algorithms to minimize the error.
Are neural networks machine learning?
Yes, neural networks are a type of machine learning. They are a subset of machine learning and are the core of deep learning algorithms. They are called “neural” because they mimic how neurons in the brain signal one another.
How are neural networks trained?
Neural networks are trained by using data and algorithms to adjust their weights and biases, which are the parameters that determine how the network processes information. The training process involves the following steps:
The network is initialized with random weights and biases.
The network receives an input and produces an output, which is compared to the desired output (also known as the target or label).
The network calculates the error, which is the difference between the output and the target.
To reduce the error, the network updates its weights and biases using a learning rule, such as backpropagation.
The network repeats these steps for many inputs until the error is minimized or a criterion is met.
The training data is usually divided into three sets: training, validation, and testing. The training set is used to train the network, the validation set is used to tune the network's hyperparameters (such as the number of layers, nodes, and learning rate), and the testing set is used to evaluate the network's performance on unseen data.
How are neural networks used to create personalization?
Neural networks create personalization by analyzing customers’ data, such as browsing and purchasing history, social media interactions, and demographic information,, and learning their preferences and needs. Then, they use this information to tailor their experience, such as by recommending products, services, or content matching their interests. For example, Amazon uses a combination of complex algorithms, called a recommender system, and neural networks to make product suggestions. The suggestions are based on a combination of the customer's previous purchases and similar purchase patterns made by others.
How do neural networks learn from experience?
Neural networks learn from experience by using data and algorithms to adjust their parameters, which are the weights and biases determining how they process information. By learning from examples and feedback, they can perform various tasks, such as speech recognition, image analysis, and adaptive control. Neural networks can also learn from each other by exchanging signals and helping each other to improve their performance.
Are neural networks artificial intelligence?
Yes, neural networks are a type of artificial intelligence. They are a subset of machine learning and are the core of deep learning algorithms. They are called “neural” because they mimic how neurons in the brain signal one another. Neural networks try to emulate the human brain, combining computer science and statistics to solve common problems in the field of AI, such as speech recognition, image analysis, and adaptive control.
Are neural networks algorithms?
Yes, neural networks are a type of algorithms. But unlike conventional algorithms, which are written to solve specific problems, the algorithms used in neural networks are designed to learn from examples and experience. Conventional algorithms are limited by their parts and can only solve problems that we already understand and know how to solve, while neural networks can adapt and improve their performance by changing their own parameters and can solve problems that are complex and nonlinear.
When were neural networks invented?
Neural networks were invented in the 1940s when Warren McCulloch and Walter Pitts developed the first artificial neural network model inspired by the biological neurons in the brain. Their work, “A Logical Calculus of Ideas Immanent in Nervous Activity,” presented a mathematical model of an artificial neuron using electrical circuits. Neural networks have evolved since then, with contributions from many researchers and applications in various fields.
What is a convolutional neural network?
A convolutional neural network (CNN) is an artificial neural network that can learn from data and perform tasks such as image recognition, natural language processing, and signal analysis. A CNN consists of three main types of layers: convolutional, pooling, and fully connected. A convolutional layer applies filters to the input data and produces feature maps that capture the patterns and features of the data. A pooling layer reduces the size and complexity of the feature maps by applying a function such as max, average, or sum. A fully connected layer connects all the neurons from the previous layer to the output layer, where the final prediction is made. A CNN can learn from data by adjusting its weights and biases using a learning rule such as backpropagation, which minimizes the error between the output and the desired output. A CNN is inspired by how the human brain processes information, but it is not identical.
What is a neural network in machine learning?
A neural network in machine learning is a computer system that tries to imitate how the human brain works. It consists of many artificial neurons that are connected to each other and can process information by learning from data. A neural network can perform tasks such as speech recognition, image analysis, and adaptive control.
What is a deep neural network?
A deep neural network is an artificial neural network with more than two layers of nodes. A node is a unit that performs some calculation and passes the result to other nodes. A deep neural network can learn from data and perform tasks such as image recognition, natural language processing, and signal analysis.
What is a recurrent neural network?
A recurrent neural network (RNN) is a type of artificial neural network that can process sequential data, such as text, speech, or video. Unlike feedforward neural networks, which only use the current input to produce the output, RNNs have a memory that allows them to use the previous inputs and outputs to influence the current output. This makes them suitable for tasks that require temporal or contextual information, such as language translation, natural language processing, speech recognition, and image captioning. RNNs consist of artificial neurons that are connected by weights and biases, which are the parameters that determine how the network processes information. RNNs can learn from data by adjusting their weights and biases using a learning rule such as backpropagation, which minimizes the error between the output and the desired output.
What is an epoch in neural networks?
An epoch in neural networks is a term that refers to one complete cycle of training the network with all the available data. It means that the network has seen and processed every example in the dataset once. An epoch comprises one or more batches, smaller subsets of the data used to update the network’s parameters. The number of batches in an epoch depends on the size of the dataset and the batch size. For example, if the dataset has 1000 examples and the batch size is 100, then an epoch will have ten batches. The number of epochs is a hyperparameter that determines how many times the network will learn from the data. Usually, more epochs lead to better performance, but too many epochs can cause overfitting, which means that the network memorizes the data and fails to generalize to new examples. Therefore, choosing the optimal number of epochs is a challenge in neural network training.
What is feedforward in neural networks?
Feedforward in neural networks passes information from the input layer to the output layer through one or more hidden layers without forming any cycles or loops. Feedforward neural networks are the simplest type of artificial neural networks, and they can perform tasks such as classification, regression, and clustering.
What is backpropagation in neural networks?
Backpropagation in neural networks is a process of adjusting the weights and biases of the network based on the error between the output and the desired output. It is a way of training the network to learn from data and improve its performance. Backpropagation propagates the error backward through the network and updates the parameters accordingly. Backpropagation is used in many supervised learning algorithms, such as stochastic gradient descent, to train feedforward neural networks for classification, regression, and clustering tasks.
What is learning rate in neural networks?
Learning rate in neural networks is a hyperparameter that controls how much the network weights are updated in response to the error. It is a small positive value, often between 0.0 and 1.0. Learning rate affects the speed and quality of the network’s training. A high learning rate can cause the network to converge faster, leading to unstable training and poor results. A low learning rate can lead to more stable training and better results, but it can also take longer to train and get stuck in local minima. Choosing the optimal learning rate is a challenge in neural network training, and there are different methods to do so, such as learning rate schedules and adaptive learning rates.
Are neural networks used in machine learning?
Neural networks are often used in deep learning, which is a branch of machine learning that builds complex models from large data sets.
Earn a Gift, Answer a Short Quiz!
Question 1
Question 2
Question 3
Get Your Gift
Try Again! IxDF Cheers For You!
0 out of 3 questions answered correctly
Remember, the more you learn about design, the more you make yourself valuable.
Improve your UX / UI Design skills and grow your career!
Join IxDF now!
Question 1
Question 2
Question 3
Get Your Gift
Congratulations! You Did Amazing
3 out of 3 questions answered correctly
You earned your gift with a perfect score! Let us send it to you.
Check Your Inbox
We've emailed your gift to name@email.com.
Improve your UX / UI Design skills and grow your career!
Join IxDF now!
Literature on Neural Networks (NN)
Here's the entire UX literature on
Neural Networks (NN) by
the Interaction Design Foundation, collated in one place:
Learn more about Neural Networks (NN)
Take a deep dive into Neural Networks (NN) with
our course
AI for Designers
.
It's Easy to Fast-Track Your Career with the World's Best Experts
Master complex skills effortlessly with proven best practices and toolkits directly from the world's top design experts. Meet your expert for this course:
Ioana Teleanu: AI x Product Design Leader (ex-Miro, ex-UiPath). Founder, UX Goodies.
Why Is AI so Important and How Is It Changing the World?
You've heard of AI and all the wonderful—and sometimes scary—possibilities. But, unlike sci-fi apocalyptic movies, AI is
420 shares
1 mth ago
Open Access—Link to us!
We believe in Open Access and the democratization of knowledge. Unfortunately, world-class educational materials such as this page are normally hidden behind paywalls or in expensive textbooks.